Ensuring Log Security: Keeping Sensitive Values Out With Types




Logs are inherently risky: small mistakes can lead to sensitive data appearing in plaintext in places they shouldn’t. No organization can eliminate the possibility that secrets will be logged, but they can better manage the risk by adding safeguards into their systems.
This post details one approach we took at Transcend to help attack this problem, by declaring fields as sensitive or not in our type system.
We found that many avenues for making mistakes with handling secrets have disappeared, and our confidence in the safety of our logs has gone up considerably.
Building in protections like these can add extra work for developers, but they can be powerful tools for increasing developer confidence that when they make mistakes the damage can be minimized.
Starting from a place of acceptance
In the past few years, we’ve seen Twitter log unhashed user passwords, Facebook logged tens of millions of unhashed user passwords, Google logged unhashed GSuite user passwords, Ubuntu’s server installer logged passwords, and many other cases of similar incidents occurred. These incidents are extremely damaging to user trust and can require extensive cleanup to prevent identity theft.
Despite the severity, it seems that whenever these incidents occur, online forums are filled with comments from developers who couldn’t possibly let this sort of mistake happen in their systems, and that Twitter, Facebook, Google, Ubuntu, and others must be worse at architecting systems than they are.
This could be true in some instances, but brushing off these cases as elementary feels disingenuous to the brilliant DevOps work each of these companies has contributed to the open source community.
If we can accept that developers occasionally make mistakes while also accepting that these breaches are unacceptable, we can conclude that safeguards that would protect against similar mistakes while simultaneously minimizing the damage would be beneficial.
How does log redaction happen now?

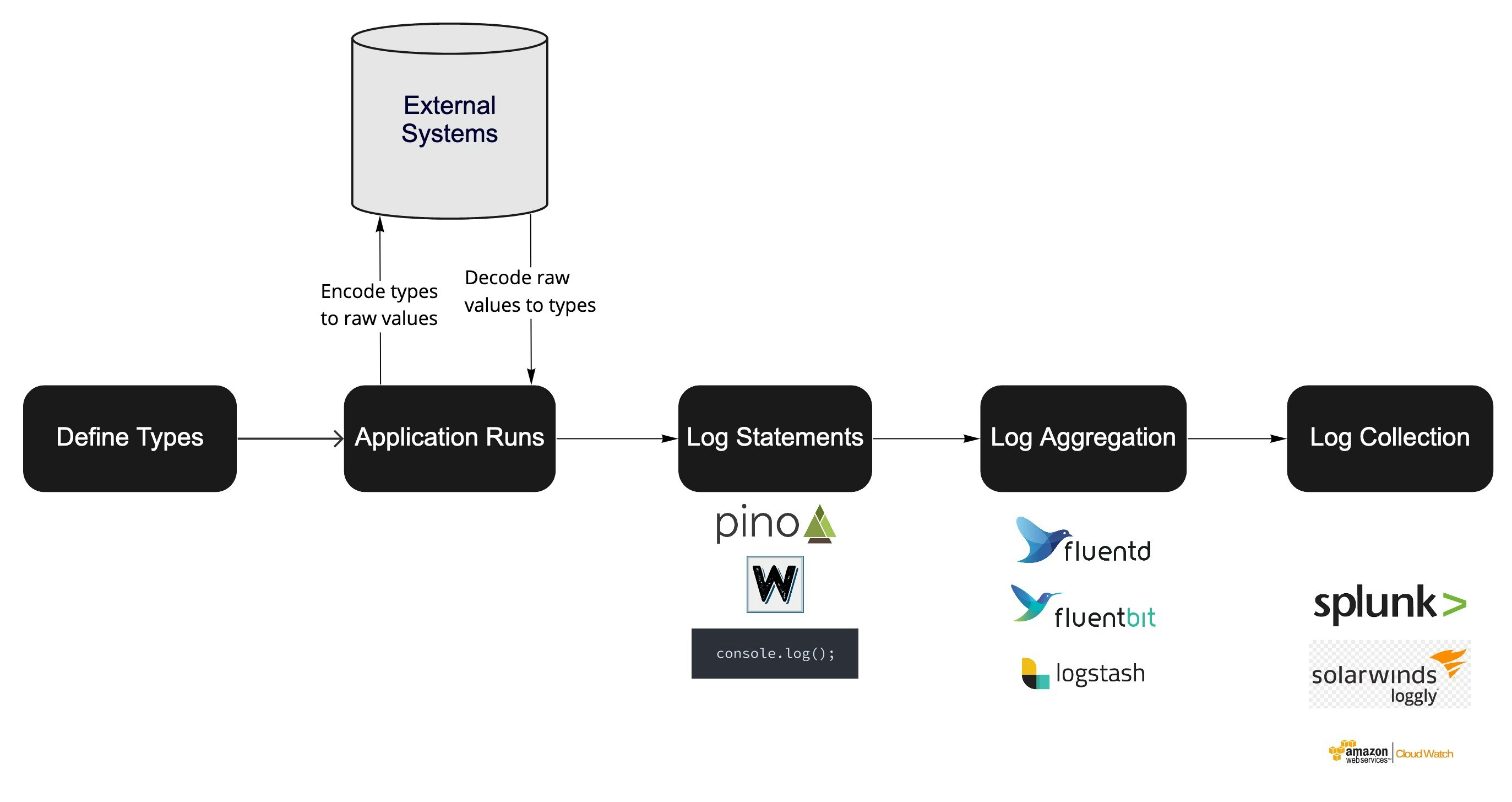
The above diagram shows how many production systems manage logs at a high level, across a variety of stacks and languages.
There is some application code that contains log statements, and those logs are picked up and enhanced by a daemon service, which then forwards the logs to a log collection service, that allows you to interact with those logs.
Throughout this pipeline, redaction can happen at a number of stages:
Application code that determines what values should be logged.
Logging libraries offer log levels to discard debug-level log statments
Many log libraries offer APIs to redact certain log paths of structured logs
Log Aggregation services offer APIs for rewriting or removing keys that could have sensitive values
Log collection services offer ways to make existing logs unsearchable if they have sensitive data
All of these levels offer a filtering system where logs that make it to the collection services shouldn’t contain any sensitive data, but holes are still possible in each step:
In your application code, your team could approve a PR that adds a sensitive field to an object that previously did not have sensitive data, without being aware of where that data is logged or consumed.
While many companies review all of their own code used in production, they may not stay up to date on all logging changes in third party dependencies. A three-level deep npm dependency that changed its error message to include more information may end up unintentionally logging more of an object than you thought it would.
The third party libraries you use can have different definitions of what information is acceptable to log at certain log levels.
Your log aggregation redaction regexes might miss user emails or other fields that use non-standard or international formats.
A misspelling in a field name or log level could lead to fields not being redacted when you think they should have.
Sometimes error messages or stack traces can add wrappers around your structured logs making path-based redaction difficult.
Log collection services de-indexing sensitive data should only be used as a last resort. If your data is in plaintext in an external system, it could have already been compromised.
As you move to the right in the diagram, getting closer to the log collection services, the filtering becomes more of a last resort approach. They are still good to have, but ultimately, it’s as you move to the left towards application code where the most effective best practices live. Your application code is where you likely have the most robust code reviews and can most easily enforce best practices like only logging the minimum number of fields.
By carefully picking what fields we want to log in structured log formats, we can have quite strong confidence that we won’t log sensitive data.
After all, the easiest way to ensure your fluentd regex that redacts social security numbers doesn’t miss a value is to just not log social security numbers!
But we’d be foolish to think that Google, Facebook, Twitter, and others don’t use structured logs with typed fields. There’s still one problem left: many structured logs have string as some field types. And strings can contain sensitive data.
This last step, and the one the rest of the article will focus on, is adding secret metadata to our typing system so that we can try to prevent these freeform string fields from presenting any data we don’t explicitly mention should be presented.
Redacting at the type declaration level
A quick note: In this blog, we’ll be focusing on Typescript and our open-source @transcend-io/secret-value library available on npm/Github Packages, but the concepts can be used across a variety of languages.
In order to help ensure that sensitive values are not included in log statements, we’ve created a new type Secret that prevents its values from being added to logs. The easiest way to show how is with this example:
import { Secret } from `@transcend-io/secret-value`; const secret = new Secret(`some secret value`) console.log(secret);
We wrap the string some secret value into a Secret<string> type that will appear as [redacted] whether you console.log it, JSON.stringify it, secret.valueOf() it, interpolate it into a string, or do just about anything else to it you could imagine in JavaScript.
If you want to modify the value of the secret without unwrapping it, you can use the map function common to many functional wrappers like const secretLenth = secret.map(rawValue => rawValue.length).
When you want to use the value stored inside the secret, you can use secret.release() to get the value some secret value back out.
The API is minimal, but it’s meant to be this way. This wrapper provides a few benefits:
It provides internal documentation to your developers that a value is sensitive, in an enforceable way that comments cannot do.
It ensures that if the
Secretvalue is included in any log statement, its value will not appear.It shifts the responsibility to determine if a value is sensitive or not from the person writing the log statements to the person defining the field.
It encourages developers to consider if it is safe to release secrets and pass their raw values to external systems, as most external libraries won’t take
Secret<T>types. As an example, you might be fine sending most of your values to theleft-padlibrary on npm, but maybe you should stick to mutating your Secret values in-house to prevent cases where a deep dependency on npm could add a log statement that would log out your sensitive value.
This paradigm can also be extended in a couple of different ways:
You could add telemetry to track who is releasing secret values, when they did it, and why they did it.
Instead of printing
[redacted]you could hash the secret values, which is what Hashicorp does with their Vault audit logs.
Summing up
At Transcend, our business is protecting users’ personal data. This requires careful thought and care to go into our application code, infrastructure, and end-to-end encryption pipelines. Keeping sensitive information out of logs is just one part of this process, but using Secret<T> has made this one part much easier.
Discover more articles