Accelerate your deploys with these 5 CircleCI optimizations
6 min read


At Transcend, we build, test, and deploy all of our application code through CircleCI. In order to maintain a quick developer feedback loop, we recently optimized our pipeline for performance.
We were able to reduce our build, test, and deploy cycle time from 22 minutes down to just 8 minutes without removing any generative or integration tests. Further, we were able to drop unit testing times on our pull requests (PRs) from over 4 minutes to a mere one minute.
This post explains how we achieved these performance gains.
Get the baseline
Let’s start with a representative job that runs JavaScript unit and integration tests using Jest. The following configuration defines an execution environment ci-node, a job named jest-unit, and a workflow named main_workflow. (CircleCI workflows run one or more jobs).
executors: ci-node: docker: - image: 123456789.dkr.ecr.eu-west-1.amazonaws.com/ci-node:our5ha jobs: jest-unit: executor: ci-node steps: # Get code from git - checkout # Restore our node_modules cache, if we’ve run this job before - restore_cache: keys: - yarn-vblog-{{ arch }}-{{ checksum "yarn.lock" }} # Make sure we are up to date with the package.json dependencies - run: yarn install # Save a cache of our up to date node_modules for future runs - save_cache: paths: - node_modules - packages/admin-dashboard/node_modules - packages/core/node_modules - … key: yarn-vblog-{{ arch }}-{{ checksum "yarn.lock" }} # Run some tests - run: yarn test:jest workflows: main_workflow: jobs: - jest-unit: # Give this job AWS credentials to access our private Docker images context: dev-ctx
In particular, the jest-unit job does something pretty common in continuous integration (CI): it uses our private Docker image to create an execution environment where it then checks out code from our git repository, installs our node_modules dependencies using yarn, and then runs our tests.
This job typically takes 4 to 6 minutes to complete running. Here’s a run that took 4:30:

Without a cache (such as when the job is first run, or when the list of node modules that make up the cache is changed), it takes around three minutes to install all dependencies from scratch, and another 40 seconds to save those dependencies to the cache:

This run time isn’t terrible, but it could be much better.
Accelerate each step
With a little tinkering, almost every step in this job can be sped up. Let’s dive in:

Not at Transcend anymore (from XKCD)
1. Use 2nd gen convenience images for quick environment spin up
The “Spin Up Environment” step is responsible for creating the virtual environment in which your job will execute (hence “executor”). Pulling in an executor, in this example an entire Docker image, can be slow. Although you can specify a custom Docker image, CircleCI also provides pre-made convenience images that we have found to be very convenient.
CircleCI recently released a second-generation version of these convenience images, which promise faster spin-up times. The cimg-base repository documents everything that is installed in the base Docker Image. Because the convenience images are all built off of the same base image, they can cache very well using Docker Layer Caching.
In our example, the only change we need to make is to point to one of these new images in our executors. In our case, we can also remove our credentials used to access our private image:
executors: ci-node: docker: - - image: 123456789.dkr.ecr.eu-west-1.amazonaws.com/ci-node:our5ha + - image: cimg/node:14.3 workflows: main_workflow: jobs: + - jest-unit - - jest-unit: - # Give this job AWS credentials to access our private Docker images - context: dev-ctx
The results are pretty dramatic when the cache hits:
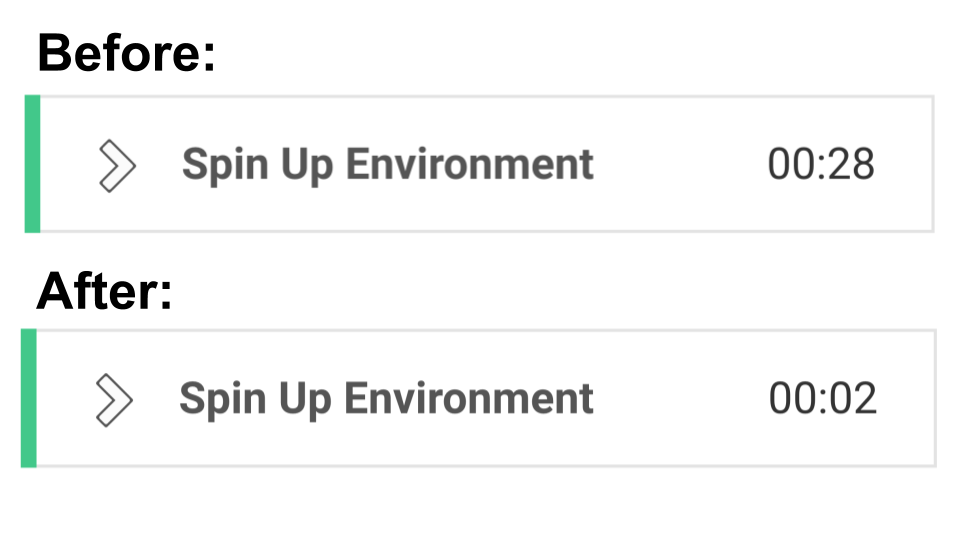
Even when the cache doesn’t hit, there are usually enough layers cached that spinning up the environment now takes less than 15 seconds (down from 30-50 seconds before).
Even more helpful than this speed, the new convenience images are Debian-based. This allows us to use Unix tools that our developers are familiar with, like the package manager apt, instead of the sometimes-confusing Alpine apk (Alpine does not include common tools like bash or jq by default).
2. Use shallow clones for swift code checkout
Repositories balloon over time, especially if you use a monorepo as we do. Even if the file size at HEAD is kept relatively small, past file blobs can stick around in the .git folder. One of the best ways to speed up git clone commands is to use a shallow checkout.
There are a few open-source CircleCI Orbs that make this optimization easy to implement. In particular, we like this one because it lets us customize any git settings we’d like.
To use this orb, at the top of your config, add:
orbs: git-shallow-clone: guitarrapc/git-shallow-clone@2.0.3
Then replace - checkout in all your jobs with - git-shallow-clone/checkout.
When we made this change, our checkout step dropped from 15-25 seconds down to 3-5 seconds just like that!
It’s worth noting that there are two reasons why someone might not use shallow checkouts:
- Some Git commands are not supported by shallow checkouts. These include fetching information from multiple branches or from deep in the Git history.
- Git providers sometimes rate limit shallow checkouts. This only becomes an issue for large workflows or frequent runs.
That said, for the majority of use cases, shallow checkouts are safe to use and can save a significant amount of time.
3. Untar in RAM for rapid cache restores
Caching can be a wonderful, run-time-saving thing. That said, accessing our large node_modules folder (nearly 300MB) from the CircleCI cache could sometimes take longer than starting from scratch with a fresh yarn install.
Internally, CircleCI manages caches and workspaces by putting files into a tarball and uploading that compressed tar file into Amazon S3. When you request a cache, CircleCI downloads the tar file from S3, validates that the file is the one that was requested, and then untars it.
Because node_modules can have thousands of files, even with lightning-fast network speeds, disk IO can slow down the untar process significantly.
In our example, restoring our cache took 1:07. Only 6 of those seconds were spent downloading and validating, while decompressing the files took over a minute. In the worst-case scenario, this cache restore step could take up to 3 minutes to complete.

Lucky for all of us, as of the April 7th, 2020 CircleCI release, CircleCI supports mounted RAM disks on Docker executors.
Using these RAM disks has dropped the restore_cache run time down to a consistent 10–20 seconds. These are the changes we made to achieve faster results:
executors: ci-node: docker: - image: cimg/node:14.3 + # Upgrade the resource_class for a bit more RAM for consistent builds + resource_class: medium+ + # Updated so we can build using RAM + working_directory: /mnt/ramdisk jobs: jest-unit: executor: ci-node steps: - git-shallow-clone/checkout - restore_cache: keys: - - yarn-vblog-{{ arch }}-{{ checksum "yarn.lock" }} + # Reset the cache to vblog2 (from vblog) in order to force a refresh + # The old cache would write out the files to our old `working_directory` path + - yarn-vblog2-{{ arch }}-{{ checksum "yarn.lock" }} - run: yarn install - save_cache: paths: - node_modules - packages/admin-dashboard/node_modules - packages/core/node_modules - ... key: yarn-vblog-{{ arch }}-{{ checksum "yarn.lock" }} key: yarn-vblog2-{{ arch }}-{{ checksum "yarn.lock" }} - run: yarn test:jest
Just like that, our caches are lightning quick:

In order to use this approach, your repo and its dependencies must be able to fit in RAM. While the larger resource_class costs more money, because our jobs now finish in about half the time, the cost difference has been negligible.
And while your mileage may vary, give larger instance sizes a try and see if they work for your use case.
4. Parallelize jobs for expedited workflows
Improved caching and access to caches is all very well and good, but when dependencies change, caches need to be updated. In these cases, the yarn install step will need to do more work, as well as the Saving Cache step, adding an extra minute or so to our pipelines. To solve this problem, we decided to play around with parallelization.
First, we tried saving the cache in a single job separate from all of our other jobs. Each subsequent job could then restore the cache from its saved location in the workspace instead of saving the cache as part of all of our jobs, including the jest tests:
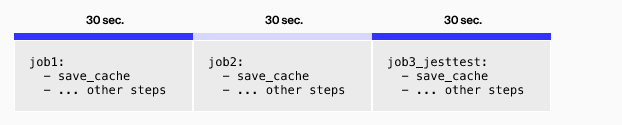
Became

We were disappointed by the results of this approach: combined, these jobs took even longer. It could take almost 2 minutes to store our dependencies in the workspace, and that step needed to complete before we started our jest job.
To get around this problem, we changed the way we split our jobs. We divided them into first-level jobs that can rely on the global cache for dependencies (and don’t depend on the completion of other jobs) and everything else. Then we added a new first-level job, cache-deps, that cached all dependencies for any job that ran after the first level.
Our new pipeline runs all first-level jobs immediately, and then anything with a dependency. This division has the added benefit that most of our first-level jobs no longer need to write out to the cache, as cache-deps now takes care of that.
In our config, this looks like:
jobs: + cache-deps: + parameters: + key: + type: string + executor: ci-node + steps: + - git-shallow-clone/checkout + - restore_cache: + keys: + - << parameters.key >> + - run: yarn install + - save_cache: + paths: + - node_modules + - packages/admin-dashboard/node_modules + - packages/core/node_modules + - ... + key: << parameters.key >> jest-unit: executor: ci-node steps: - git-shallow-clone/checkout - restore_cache: keys: - yarn-vblog2-{{ arch }}-{{ checksum "yarn.lock" }} - run: yarn install - - save_cache: - paths: - - node_modules - - packages/admin-dashboard/node_modules - - packages/core/node_modules - - ... - key: yarn-vblog2-{{ arch }}-{{ checksum "yarn.lock" }} - run: yarn test:jest workflows: main_workflow: jobs: + - cache-deps: + key: yarn-vblog2-{{ arch }}-{{ checksum "yarn.lock" }} - jest-unit
By splitting up our jobs to be as small as they possibly can be – especially those in our critical path – and removing unnecessary cache dependencies, we’ve reduced runtime from four and half minutes to under two:

While infinite parallelization won’t speed things up (Amdahl’s Law is real and common set up time adds up!), we have realized some significant improvements by splitting up jobs. You can, too.
5. Use historic test timings to inform hyper-efficient test parallelization
When CircleCI runs jobs, they also have a sidecar docker image running called the CircleCI Agent that can be communicated with via the circleci command line tool. The circleci command line tool is installed on all executors.
One of the coolest features of this agent is the ability to split tests by historical timing data so that you can run tests in parallel very efficiently. If tests A, B, and C take 10 seconds, and test D takes 30 seconds, you would want to run tests A, B, and C in one thread, with test D alone in the other.
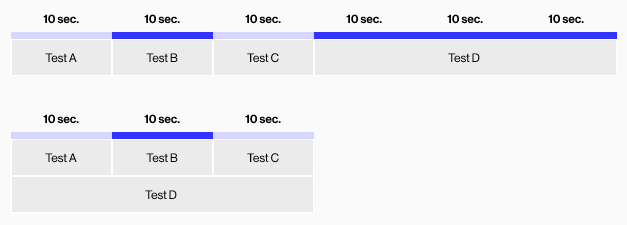
This example uses jest, but the principle should work on any testing framework that supports creating output artifacts that CircleCI knows how to ingest. To keep this blog general, I will show the updates to the CircleCI config without the specifics of using a custom jest reporter.
jobs: jest-unit: executor: ci-node + parallelism: 3 steps: - git-shallow-clone/checkout - restore_cache: keys: - yarn-vblog2-{{ arch }}-{{ checksum "yarn.lock" }} - - run: yarn test:jest + - run: + name: Create a file of all the tests to run + command: yarn test:jest --listTests | grep packages > testFiles.txt + - run: + name: Run Jest tests using test splitting + command: | + FILES=$(circleci tests split --split-by=timings testFiles.txt) + yarn test:jest $FILES + - store_test_results: + path: 'jest/test_results' + - store_artifacts: + path: 'jest/test_results' + destination: test_results
The pattern here is:
- Get a list of all the tests you want to run
- Use circleci tests split --split-by=timings to split those tests based on past output artifacts
- Update the parallelism field so that Circle will only run around one-third of the tests in each parallel sub-job.
- Store our test results so Circle can make our future runs faster
Now, we run three sub-jobs inside each call to run jest-unit that only are responsible for a third of the tests. Because we are using historical timing data, the three parts all finish in roughly the same amount of time:

Our total time is now just one minute!

And just to prove that we consistently get times around one minute, here’s a workflow where I ran 20 jobs at the same time, all of which took between 0:57 and 01:28:

Summing Up
By leveraging CircleCI’s advanced features (and one Git trick), with a few extra lines of configuration we were able to reduce our testing and deployment time by 75% while maintaining the same test coverage. These implementations will work for anyone. The more layers of dependency your CI configuration holds, the more our optimizations will help save deployment time.


By David Mattia