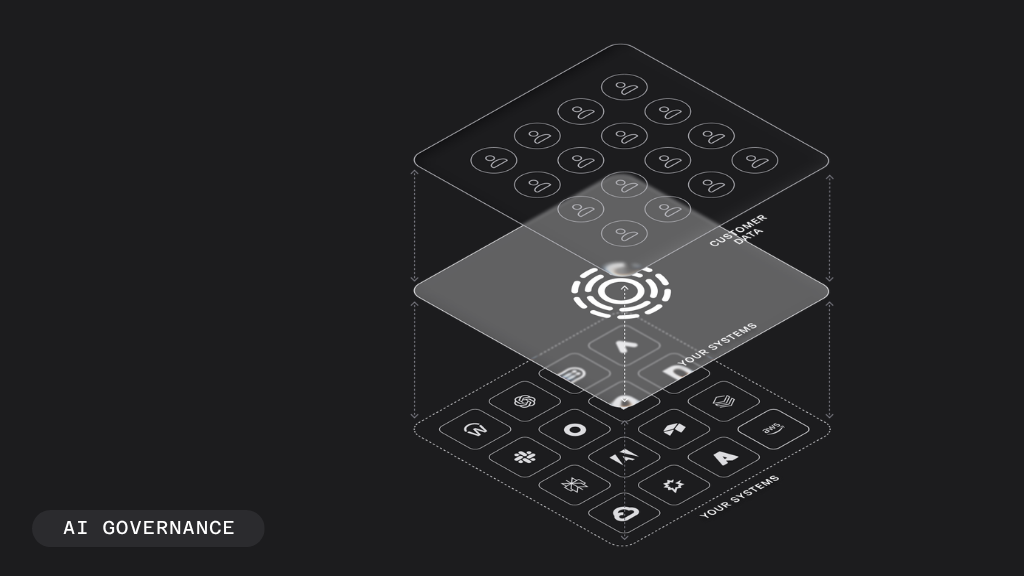
A three-stage maturity model for enterprise data permissioning
12 min read


We are living through the single largest expansion of consumer data use cases in a generation. Every team in every business now wants to do something new with the customer data already held by the company.
Marketing wants an agent that hyper-personalizes every message. Product wants to ship a copilot that knows everything the company knows about the user. Data science wants to fine-tune a foundation model on the company's data. Customer service wants to deploy an agent that resolves tickets end-to-end. The CEO wants all of it, yesterday.
Sooner or later, every one of those teams hits the same wall: “Can I use this data?”
Most enterprises cannot answer that question in real time, at the level of confidence the business needs. They answer it with meetings, exceptions, and broad exclusions: Exclude all of Europe. Exclude every identifiable minor. Exclude this entire data category. Exclude this entire use case.
Because the only enforceable controls are blunt, the business loses access to data it could legitimately use. Or, it keeps moving without sufficient proof that the data use is allowed, taking on a risk that surfaces later in an audit or headline.
Neither outcome works anymore. The answer to "can I use this data?" can no longer be a meeting. It has to be a system.
Two structural components are at the root of why this is harder than it was two years ago.
- Businesses collected nearly all of the customer data they hold for one set of purposes. The user signed up for a service, subscribed to a newsletter, created an account, or opted into product analytics.
- Now businesses want to use that same data for a different set of purposes, including agentic AI, foundation-model training, retail media activation, or the dozens of internal data products that now sit on every CIO's 2026 roadmap.
All of these purposes significantly expand the scale at which data is used, but at the moment the original permissions were granted, they weren’t yet on anyone’s radar.
For years, the industry treated this as a privacy problem: deploy a consent banner, conduct a policy review, get sign-off from legal, and move on. When activation was slow and the highest-stakes use case was an email campaign, that worked. When every team has a new use case every quarter, and the use cases themselves involve foundation models, autonomous agents, and audiences that move at machine speed, that process breaks down.
From a decade of conversations with the people who lead this work (CIOs, CDOs, CMOs, heads of data engineering), I’ve learned that the answer has layers, and most enterprises only address the first one. There’s a maturity curve here, and where you fall on that curve determines whether your AI roadmap ships or stalls.

Learn more about the three stages of enterprise data permissioning maturity
Watch the full recordingStage 1: Frontend consent
This is where everyone starts. A banner on the homepage. A toggle in a settings page. A cookie preference center that asks the user to accept or reject categories of trackers, with region-aware variants for GDPR, CCPA, and the rest of the U.S. state patchwork.

Stage 1 has its place. It is the first impression of your privacy program and, in much of the world, a regulatory requirement. But its scope is too narrow. It almost exclusively governs whether data can be collected in the first place. The signal it produces is tied to a single browser session. Close the tab, switch devices, clear the cookies, and the choice is gone unless something downstream caught it.
In most enterprises, nothing downstream caught it. The choice the user made in the banner does not propagate into the warehouse, CDP, activation platforms, marketing tools, model training pipelines, or agents that read against any of those systems. The substantive work happens against records that the banner never reached: analytics, modeling, personalization, audience activation, and agent actions.
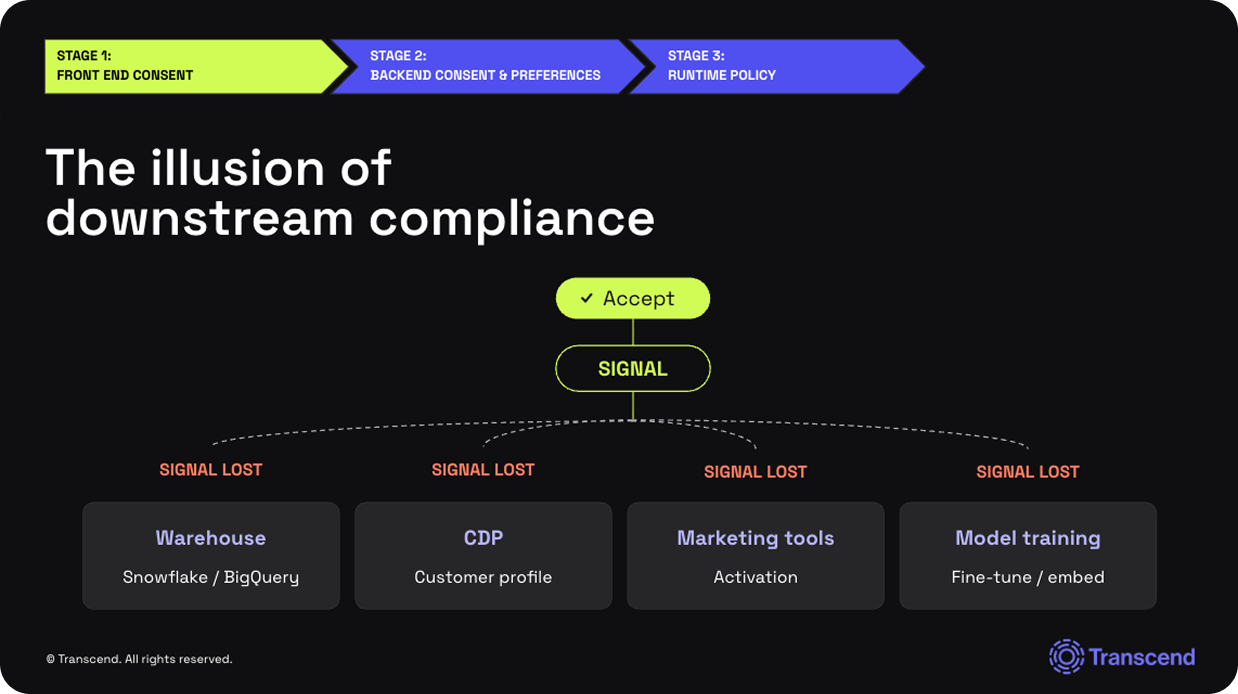
If consent and the universal opt-out signals required by modern state privacy laws are not propagating into your backend, you are honoring user choice on the front page and absorbing the risk everywhere else.
Stage 1 is necessary, but it’s not enough.
Stage 2: Backend consent and preferences
Stage 2 is harder. The business starts maintaining a durable record of each user’s consent and preference choices, stored against the user identity, propagated to the systems that actually process data, and respected over time. The cookie choice on the homepage becomes a preference on the user record. The opt-out on the privacy page becomes a flag the warehouse and marketing tools can read.
This is where most "mature" privacy programs sit today, and it’s a real step forward. However, it does have a ceiling because a stated preference is not a complete answer to "Can I use this data?"
Consider what a backend consent record does not tell you.
It doesn't tell you what to do in the absence of a choice
Most users have never expressed a choice. The default state is the actual policy for the overwhelming majority of records, and what counts as a permissible default is a function of jurisdiction, sector, and purpose. The default for a user in Munich is not the default for a user in Houston, and neither is the default for a user covered by HIPAA. Stage 2 stores the user's voice. It’s silent when the user is.
It doesn't tell you who the user is
A user might be a child under 13, in which case COPPA requires verifiable parental consent before you can collect almost anything. Or they might be a minor under one of the rapidly proliferating state-level age-appropriate design codes, which don't ask the parent at all. Those laws force you to apply high-privacy defaults and turn off profiling regardless of what anyone consented to. The consent flag says "yes," but the age says "no." The age wins.
It doesn't capture the constraints baked into the structure of the business itself
Every regulated industry layers its own rules on top of consent, and those rules depend on facts that no consent record encodes: how the relationship is structured, how the service is paid for, who the parties are, what category of activity is in play.
- In healthcare: The federal Anti-Kickback Statute prohibits knowingly exchanging anything of value to induce or reward referrals for items or services payable by a federal healthcare program. Even with a valid HIPAA authorization on file, sharing the same patient record with one downstream partner may be fully permissible, while sharing it with another could be a legal violation—depending entirely on how the relationship is structured and how the care is funded. Consent isn’t always enough. The same data-sharing arrangement can be perfectly fine for a self-paying patient and a federal offense if the patient is on Medicare.
- In telecom: CPNI rules under Section 222 of the Communications Act govern what carriers can do with their customers' call detail records and service usage data. A customer might broadly opt into marketing, but CPNI requires a separate, specific opt-in before that information can be used to market services outside the customer's existing service category. The marketing flag says go. CPNI says stop, until the customer specifically says go for this purpose.
- In financial services: The Gramm-Leach-Bliley Act governs how nonpublic personal information can be shared with third-party companies outside the organization, while the Fair Credit Reporting Act and its Affiliate Marketing Rule govern how that same information can be shared and used for marketing within affiliated companies. A customer gets distinct opt-out rights under each. PCI DSS limits where cardholder data can flow regardless of consent. State insurance and securities rules constrain how customer data can be used to drive recommendations and automated decisions.
An enterprise can have a clean consent record and still be a dozen rules away from being allowed to do what it wants to do.
It doesn't capture the business's own commitments
Your privacy policy says one thing. The DPA you signed with your largest enterprise customer says another. The CISO has a standard for which data classifications can flow to which environments. The contract your AE signed last quarter promised a customer their data would never train a model. None of those commitments live in the consent record. All of them are enforceable.

Stage 2 stores the user's voice. However, it does not on its own encode the law, context, or promises the business has made. Even enterprises that have invested heavily in capturing and storing consent end up in the same place: they have the data, but still can’t get a straight answer on whether a given use is allowed.
Stage 3: Runtime policy
Stage 3, Runtime Policy, is where the question actually gets answered. Runtime Policy takes the user's consent and opt-outs (where they exist), the user's preferences, as well as everything else the decision actually depends on, including the:
- User’s jurisdiction, age, and relationship to the business
- Sensitivity classification of the data
- Purpose being proposed
- System requesting it
Those inputs run through a policy that returns a decision, in real time, at the point the data is about to be used.
The right unit of analysis is per record, per purpose, and per person. The same record can be a yes for product analytics and a no for model training. The same user can be in-bounds for sensitive-data processing in Houston and out-of-bounds for the same processing in Munich. Two records side by side in the same dataset can come back yes and no for the same query, because consent, jurisdiction, and sensitivity attach to the record, not the table. Anything less is guessing, and regulators, customers, and boards have stopped accepting guesses.

This is a policy engine. It runs as code at every policy enforcement point (the place in your system that blocks using the data if policy prohibits it). That means inside tools like Snowflake and Databricks, inside the personalization engine, inside the marketing platform, inside the agent runtime, inside the training pipeline. It does not depend on a human catching the issue in review. It depends on the systems themselves knowing the rules and refusing to act when the rules say no. Consider these examples:
Example: Automated system syncs
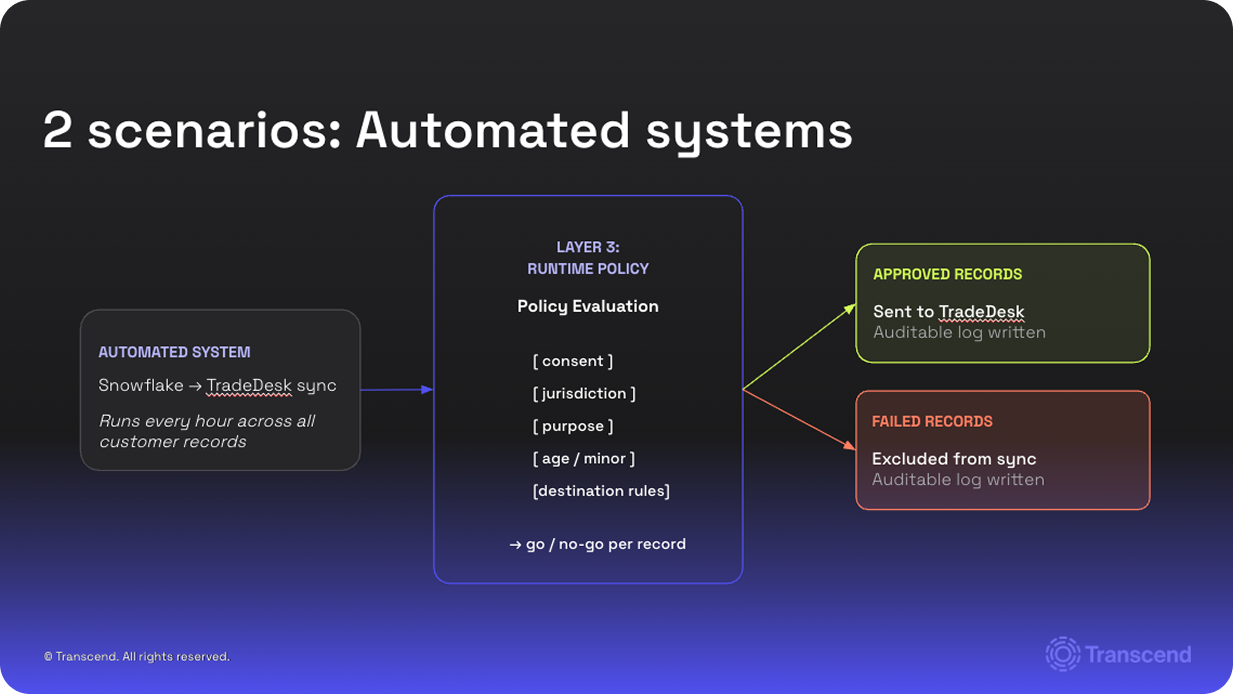
An automated system syncs a Snowflake customer list to Trade Desk for targeted ads and that sync runs every hour across all customer records. Without runtime policy, the system does one blunt check: who has consent and hasn’t opted out. That creates two potential problems at once:
- Under-advertising: The business misses the opportunity to advertise to people who have agreed to see ads
- Over-advertises: The business reaches out to people it shouldn’t – wrong region, wrong age, wrong jurisdiction – absorbing the risk
With runtime policy in place, every record is evaluated against consent, jurisdiction, purpose, age, and destination rules on every sync. The marketer gets back an expanded, fully permissioned audience. The CMO has a defensible record. The same fix that reduces risk also grows the reachable pool.
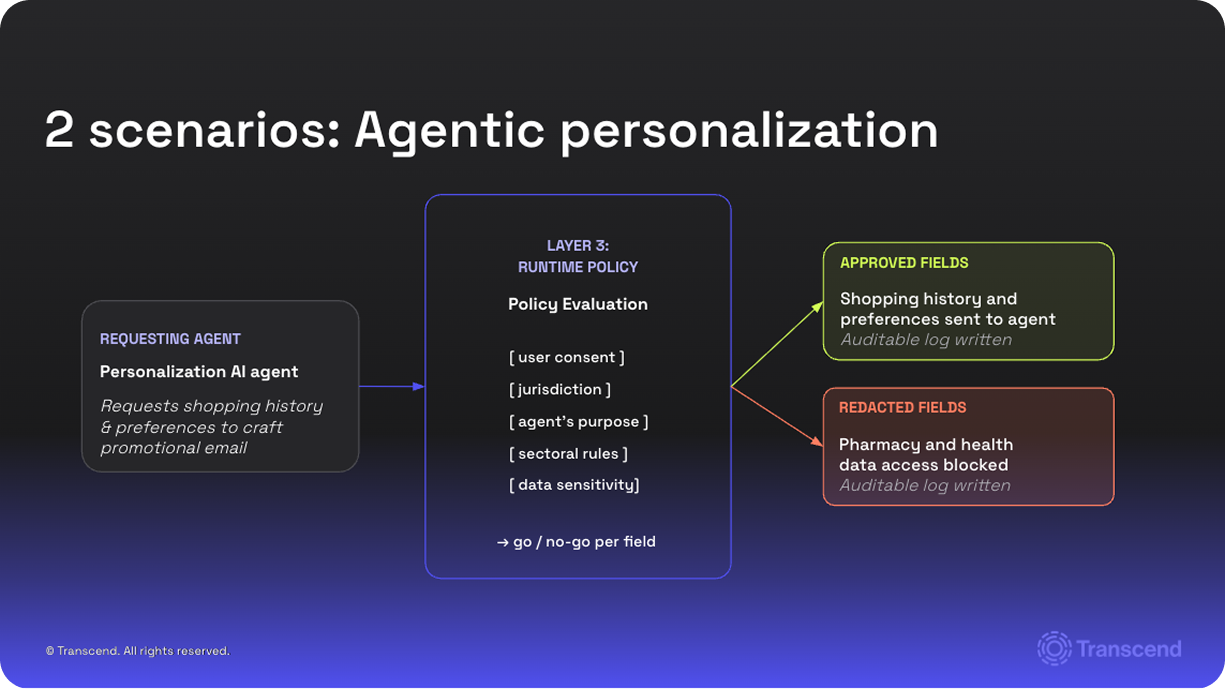
Example: Agentic personalization
A personalization AI agent is built to craft promotional emails using shopping history and customer preferences. But the retailer also operates a pharmacy department. Without runtime policy, the agent reaches into health-adjacent data it has no business touching. That agent sits in a sandbox. Not because it does not work. Because no one can prove it is safe to ship.
With runtime policy in place, every field the agent requests goes through a policy evaluation: user consent, jurisdiction, the agent's declared purpose, sectoral rules, and data sensitivity. Shopping history and preferences are approved and sent to the agent. Pharmacy and health data are blocked. An auditable log is written either way. The agent moves from pilot to production. The next agent the business deploys inherits the same enforcement, without re-litigating the data question from scratch.
That is the difference between consent management and a permission layer. Consent management records what the user said. A permission layer decides what the business can do.
The state most enterprises are actually in
What I see most often are organizations stuck between Stage 1 and 2, with no infrastructure at Stage 3. Consent gets captured, some of it makes it to the backend, and some preferences end up stored against the user record. And then, when a team wants to do something new with the data, the answer still comes from a person.
Legal can tell you what the policy is. Legal cannot tell you, at the level of an individual record, who has consented to what, who is a minor, who lives in which state, who is covered by which contract, who is paying through Medicare.
The information needed to make the decision is sparse, fragmented, and scattered across the business in the CMP, CRM, warehouse, CDP, contract repository, and the regulatory matrix at outside counsel. The conversation between legal and technical teams becomes an exercise in blunt simplification, and the business loses access to data it could legitimately use.
More often, the request goes into legal review and sits there. The team that wanted to ship a model is now waiting on legal's calendar. The team that wanted to activate an audience is negotiating exceptions. The team that wanted to deploy an agent is told to come back next quarter. Activation slows to the speed of the slowest manual review, and AI adoption (the thing the CEO is measuring everyone on) stalls.
This is what drives the "capability overhang" in enterprise agentic AI. The gap is between what models and agents can do in the lab and what enterprises will actually let them do in production.
The capability is there. The data is there. What’s missing is the ability to prove, at runtime, what data a given agent is allowed to read, for which customer, for what purpose.
Without that proof, nothing ships. The agent that could resolve the support ticket reads from a redacted view and fails. The model that could personalize the offer is trained on a sanitized dataset and underperforms. The retail media network that could compete with the platforms launches against a fraction of the audience the business actually has. The largest AI programs in the Fortune 500 are stalling on the same issue, and the AI roadmap slips, quarter by quarter, on a problem that looks like a privacy problem and is actually an infrastructure problem.

Learn how enterprises are using runtime policy to unlock first-party data for AI and personalization in 2026
Watch the recordingWhy this is an infrastructure problem now
The volume of new use cases has gone up by an order of magnitude, as has the regulatory surface and the number of records the enterprise holds. As a result, the review queue has grown faster than any privacy or legal team ever could. The answer to "can I use this data?" can no longer be a meeting. It has to be a system.
That system is policy-as-code: the law and contracts, the business's own rules, and the user's choices encoded as policies that execute at every point where data is requested. The policy is authored by the people who own the rules (legal, privacy, security) and enforced by the systems that touch the data, without a human in the loop for every decision. The output is a real-time, auditable, per-record answer every time the question gets asked.
This is the bet we made when we built Transcend. It’s the bet the privacy and data leaders I respect most are now making inside their own organizations. They are turning their function from a review committee into an infrastructure team. They are writing the policies down in a form a machine can execute. They are deploying enforcement at the points where data actually moves. They are giving the business something it has never had: an answer that arrives in milliseconds, with a paper trail, every time.
What this means for data leaders
If you lead data, privacy, or security at an enterprise that is serious about AI, "can I use this data?" is the question your team will be measured on. It determines whether the AI roadmap ships or stalls. It determines whether audiences get activated or quarantined. It determines whether the rest of the business sees your team as the one that ships, or the one that blocks.
You will not answer it with a policy document, a banner, or a quarterly review board. You will answer it with infrastructure: a permission layer that is encoded, enforced, and provable, where every system that touches customer data already knows the answer, because the answer travels with the data in real time, across every layer of the stack.
That is the work. Done right, it makes the enterprise's data AI-ready, so the rest of the business can finally ship against it. And it turns privacy and data leaders from the people the business has to wait on into the people it cannot ship without.

Ready to move from policy to real-time enforcement?
Reach out to our team

By Ben Brook