Our journey to a serverless architecture with Lambdas
7 min read


At Transcend, our mission is to put users everywhere in control of their data.
At the core of this mission is our data privacy infrastructure, which for companies takes care of everything from allowing their users to submit privacy requests to our customers, orchestrating personal data from hundreds of SaaS partners and internal databases, and returning data found to the data subject.
But with that comes an inherent challenge—running hundreds and thousands of processes in parallel, all the while keeping request completion times to a minimum. While our platform could technically handle current volumes in parallel with low turnaround times, we knew there were low-hanging architectural improvements that could get us to a place of handling volumes of greater magnitude.
This led to a reconnaissance mission into Serverless territory, and as we are an AWS-only shop, our prime candidate was AWS’s Lambda. This blog post chronicles our efforts to move most of our privacy request processing workflows to use Lambda functions from a more traditional monolithic service.
Our goals with the project
Before we go any further, let’s first touch on the objectives we were hoping to achieve with this project.
In the short term, we wanted to quickly scale our ability to serve hundreds of thousands of privacy requests instantaneously for our customer base. At the same time, we sought to break apart our monolithic application to get to much faster builds and deploys.
In the long term, the migration sought to bring more modularity to our codebase and platform. We wanted to be able to scale different parts of our platform independently, enable smoother transitions when pushing big changes, and process and deploy our services and events on a more granular basis.
What did our previous workflow look like?
Prior to the introduction of Lambda functions as our primary way of processing data subject requests, our application’s backend was deployed in an Elastic Container Service (ECS) cluster as a monolithic application. We had a single backend “service” that would perform multiple tasks, such as invoking remote APIs, scheduling and running workflows, and acting as the server for our customer-facing API.
The bulk of our workflow involves invoking SaaS APIs using metadata from a privacy request. That involves locking the appropriate database rows to prevent multiple application threads from acting upon the same privacy request.
Unfortunately, this approach didn’t scale well with multiple application threads or when faced with unexpected spikes in incoming requests.
Enter Lambda functions
Lambda functions are self-contained pieces of code, usually deployed by uploading a zip archive containing the code to run, with functions configured using the AWS UI or a configuration file. They are analogous to functions in your code in the sense that you pass arguments to your function and operate on the response returned. However, instead of deploying your entire application, if the function code changes, you only need to re-deploy the specific function.
Lambda functions are built on the Serverless philosophy, in that you don’t need to worry about the actual hardware running your code and instead can focus on writing code, letting AWS handle the actual provisioning and runtime requirements of your function.
What does it look like now with Lambdas?
So what’s changed?
With Lambdas, we now send messages to a Simple Queue Service (SQS) queue that triggers a Lambda function. The message describes the workflow to be run along with the parameters required to invoke the remote APIs, among other things. The results of the Lambda function’s execution are stored in a DynamoDB table, which is regularly polled by our backend service. These results are then ingested in batches into the database to update the application’s state, presented to the user.
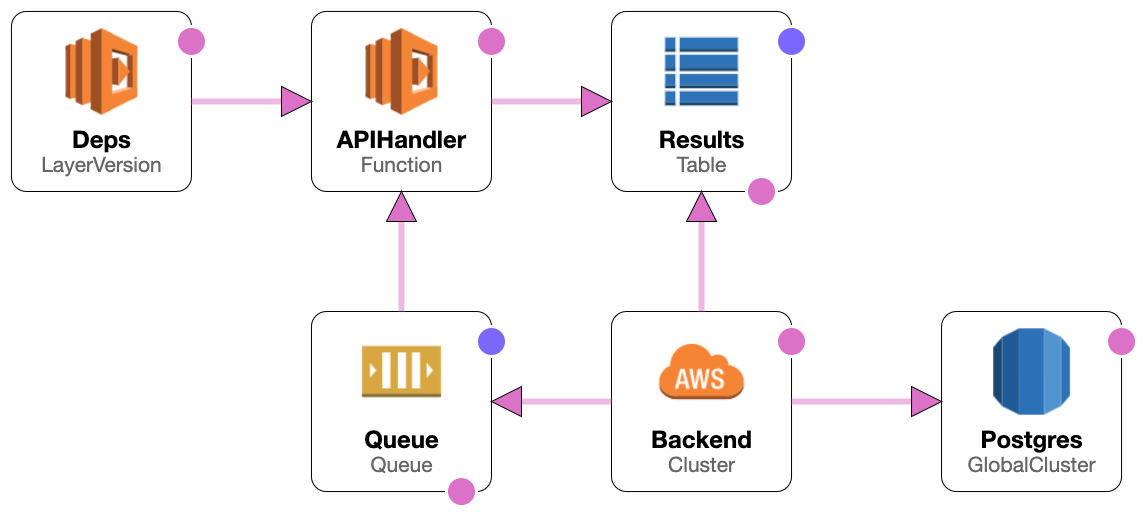
The asynchronous nature of this processing now means that thread execution times for the backend service are now less than a second, instead of multiple minutes on average with our earlier approach.
But what happens to messages that fail to process, whether it’s because a SaaS API rate limits us, there’s a bug in our function code, or something else entirely?
There are a couple of different ways we handle error states. In the case of API rate limits, or if we encounter a temporary error state, we retry the event after waiting for a short period of time. If we encounter a state where a bug in our application code is causing messages to fail processing, we send our messages to what’s called a Dead Letter Queue (DLQ) for analysis of the failed messages and their error stacks. We’ll talk about DLQs later in this post.
How we did it: Implementing Lambda functions
As mentioned earlier, we knew that our monolithic approach was not sustainable in the long term, as the sheer volume of privacy requests we were handling increased. Based on earlier attempts to increase our processing capacity by attempting to increase the number of application threads or the size of the database to cope with the extra connections, we knew some of the bottlenecks in our architecture would have to be addressed before we could grow.
We were also aware that we would have to adopt a more asynchronous approach to processing privacy requests and rely less on interacting with the database at every turn to update the application state. And as previously mentioned, we are an AWS-only setup, meaning AWS’ Lambda became our prime choice.
Invoking our Lambdas
There are multiple ways to invoke a Lambda function, such as using AWS’s API Gateway, using a Simple Notification Service (SNS) topic or an SQS queue trigger, or even the AWS API directly.
Considering our need for asynchronous processing, we chose to go with the message queue approach, with SQS and Apache’s Kafka as our primary candidates. In the end, SQS won for its ease of use, first-class integration with the AWS ecosystem, and relatively lightweight setup.
We also decided to go with the Serverless framework over AWS’s Serverless Application Model (SAM) framework, as the former is much more widely used, and its configuration syntax is much easier to parse for humans, things we hoped would mean an easier time finding solutions if, and when, we ever did run into issues.
Spoiler: we ran into a number of issues, and while the Serverless framework documentation and forums were enough to resolve most of them, there are still some rough edges.
For example, Serverless does not support creating a DLQ for a regular message queue using its config syntax. Fortunately, they support using Cloudformation configuration syntax blocks in your Serverless configuration, which meant that we were able to create and link the two queues and then refer to both of them in the rest of our Serverless configuration.
service: handler-lambda plugins: - serverless-webpack provider: name: aws runtime: nodejs14.x region: eu-west-1 timeout: 300 memorySize: 512 functions: handler: name: handler handler: src/handler.handler events: - sqs: arn: Fn::GetAtt: - HandlerQueue - Arn resources: Resources: HandlerQueue: Type: 'AWS::SQS::Queue' Properties: QueueName: 'handler-queue' RedrivePolicy: deadLetterTargetArn: 'Fn::GetAtt': - HandlerDeadLetterQueue - Arn HandlerDeadLetterQueue: Type: 'AWS::SQS::Queue' Properties: 38 QueueName: 'handler-dlq'
Packaging our Lambdas
Next, let’s talk about how we package our code onto the Lambda function itself.
We used Webpack to bundle our code, given that the serverless-webpack plugin is one of the most downloaded and mentioned plugins in the Serverless ecosystem.
We also decided to package and deploy our monorepo code and external dependencies (like request-promise, lodash, bluebird, etc.) separately, as this allows us to create the bundle for external dependencies once and re-use it for each of our hundreds of Lambda functions, drastically cutting down on deployment times.
As part of this bundling approach, the webpack config had to be modified to bundle only our monorepo dependencies, ignoring all external packages.
const nodeExternals = require('webpack-node-externals'); module.exports = webpackMerge(commonConfig, { externals: [ nodeExternals({ allowlist: [‘monorepo-package-a’, ‘monorepo-package-b’, …] }) ] });
How to spin a good “yarn” (Classic and Berry)
Midway through this project, we began looking into converting our Yarn v1 workspaces into Yarn v2 for multiple reasons, chief amongst which were the tremendously shorter install times on both local and CI and lower disk space usage. In the end, we were able to move our project to use Yarn v2, but this came with pretty big changes to our entire Serverless deployment workflow. We’re planning on publishing a chronicle on this migration in a future post, so stay tuned!
Yarn v2 does away completely with node_modules folders and patches the require/import functions in NodeJS to redirect any dependency import calls to use the new Yarn Plug n’ Play cache system, when running code using the yarn run … command. Yarn v2 uses a map file, which allows NodeJS’s require() to understand how to import packages from Yarn v2’s cache.
The changes we had to make were twofold:
- Rewrite the external dependency bundler code, mentioned in an earlier section, to use the Yarn v2 APIs to install our external dependencies to a particular folder and create a Yarn v2 map-file specifically for this folder.
- Use the Webpack Banner Plugin to load the PnP map file before any code is executed to allow NodeJS’s require() to import dependencies from the right place.
const { BannerPlugin } = require('webpack'); module.exports = webpackMerge(commonConfig, { plugins: [ new BannerPlugin({ banner: `require(‘/path/to/pnp.cjs’).setup();`, raw: true, }), ], });
Rewriting our application to use Lambdas
After figuring out how to package and deploy our Lambda functions, we were ready to start testing Lambdas as part of our privacy request workflows! But, we weren’t quite ready to roll out untested code to customers in production and had to find a way to do a phased switchover.
The approach we used was to start switching over a few of the least-used workflows to Lambdas, testing extensively, and patching any issues. We found that this approach worked best as it allowed us to control the “blast radius” for any issues we found and move quicker, refining our Lambdas development and deployment processes.
The main downside to this approach was that we had to maintain two versions of the workflow logic — one in the monolithic backend service and another in the Lambda versions, but the fact that this was temporary made it an easier pill to swallow.
Putting Lambdas out into the world
With these new Lambda functions and their associated infrastructure (SQS queues, DynamoDB tables), we went from 0 to over 300 functions! Our deploy process at the time was quite simple where we would build a Docker image, upload it to the Elastic Container Registry (ECR), and update the ECS tasks to use the new image.
The Serverless framework is quite useful as it also helps us deploy all the Lambda functions along with their SQS queues, IAM roles, and DynamoDB tables, with the downside being that we need to deploy each function separately.
We did look into tools like Seed.run and Serverless’ own deployment offering to deploy our new infrastructure in a parallel fashion but ultimately decided to roll our own deploy pipeline using multiple CircleCI containers in a single deploy job, as we didn’t want to hand over the keys to the proverbial kingdom to external vendors.
The deploy job is straightforward conceptually; it first indexes all the functions that can be deployed, reads a log of all deployments to find the latest version deployed for a particular function, and only creates a new deploy if a dependency of the function has changed since it was last deployed. The deploy job is then given the list of functions to deploy, and each container in the overall job deploys anywhere from 3 to 15 functions in a single run, with 15 containers running in parallel.
Summing up
To say this project was convoluted is an understatement. There were many obstacles to hurdle, quirks to work around, and rabbit holes to fall into. At the end of it, though, it’s quite clear to us that there’s a clear use case for the Serverless philosophy. It’s allowed us to scale up (and down) our compute based on workload, reduce our reliance on the database and its connection limits, and allowed us to delineate cleanly the different functions our platform performs.
While there is definitely an argument to be made against prematurely optimizing for workloads you might never see, in this case, the long-term benefits tied in very neatly with our short-term requirements, and so making this move made sense for us.

