How to use Terraform and Pulumi together to incrementally migrate infrastructure tooling
3 min read


Introduction
When you use Infrastructure as Code tools like Terraform, Pulumi, or the AWS CDK, you’ll doubtlessly need to have dependencies between your stacks/modules.
This can be illustrated by a small example:
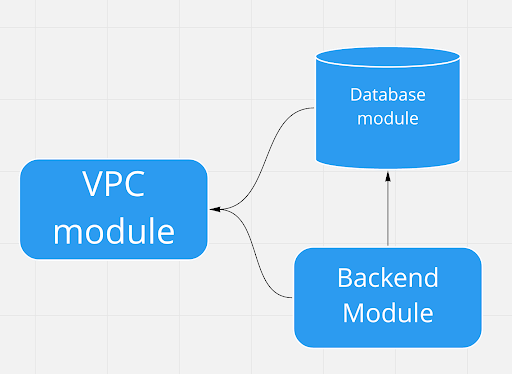
In this example, we have a piece of code that creates a Virtual Private Cloud (VPC). The code that creates our backend application and database needs to depend on the VPCs private subnet identifiers, so that we can place our backend and database inside the VPC. Likewise, our backend code will need to depend on our database code so that it can create a connection and talk to the database.
Each tool handles this scenario in a slightly different way: Terraform handles module dependencies via data source lookups or Terragrunt dependencies, Pulumi handles stack dependencies via StackReferences, and the AWS CDK handles stack dependencies via referencing CloudFormation exports.
Each of these tools makes it easy to have multiple stacks that all reference each other. This blog post will focus on how to use Terraform modules and Pulumi stacks interchangeably, with each having the ability to consume the others outputs.
This opens up two potential outcomes for your company:
- Some teams at your company can use Terraform while others use Pulumi.
- It becomes possible to migrate incrementally from one tool to the other, so you can have intermediary steps where some modules/stacks from one tool depend on module/stack outputs from the other.
Let’s explore how each tool can natively read the other’s outputs.
Reading Terraform outputs from Pulumi
If you are replacing a Terraform module that depends on other Terraform modules, your new Pulumi stack will need to be able to reference the dependency’s terraform outputs. Pulumi already wrote a really nice blog on how to do this, so we’ll keep this section nice and short.
When you made your Pulumi module, you had to write your statefile to a specific backend state. In Pulumi, using Typescript, you can use the @pulumi/terraform package on NPM to reference the Terraform module’s statefile to consume its outputs. If you are using a different language in Pulumi, there should be a similar tool to grab Terraform state.
As some quick examples, here’s a way to grab a Terraform state output value if you chose the S3 backend:
import * as tf from "@pulumi/terraform"; const remoteState = new tf.state.RemoteStateReference("s3state", { backendType: "s3", bucket: "pulumi-terraform-state-test", key: "test/terraform.tfstate", region: "us-west-2" }); // Use the getOutput function on the resource to access root outputs 11const vpcId= remoteState.getOutput("vpc_id");
And here’s a way to grab a Terraform state output value from a Terraform Enterprise backend:
import * as pulumi from "@pulumi/pulumi"; import * as tf from "@pulumi/terraform"; const config = new pulumi.Config(); const ref = new tf.state.RemoteStateReference("remote", { backendType: "remote", organization: "pulumi", token: config.requireSecret("terraformEnterpriseToken"), workspaces: { name: "test-state-file" } }); // Use the getOutput function on the resource to access root outputs const vpcId= remoteState.getOutput("vpc_id");
Note: These examples are borrowed from the @pulumi/terraform documentation as of the time of this writing, but you should check the official docs yourself in case there are any API changes.
And just like that, your Pulumi stacks can depend on your Terraform modules.
Reading Pulumi outputs from Terraform
If you are replacing a Terraform module that other Terraform modules depend on, you’ll need to update those to consume your Pulumi stack’s outputs.
This direction was a bit tougher for us, as Terraform has no built-in way to consume Pulumi outputs. We started out by trying some paths that worked, but we weren’t thrilled about, like having Pulumi write out SSM parameters or Vault secrets that Terraform could read in via data sources.
But those solutions were unideal because:
- They required writing extra Pulumi code to create those resources
- On the Terraform side, it was unclear where those Pulumi outputs were coming from, as Terraform only knew it was reading in SSM/Vault values
- These solutions just felt hacky, as they weren’t using native state features of Terraform/Pulumi
Our solution was to create an open source Terraform provider that can fetch and parse Pulumi statefiles. This provider offers a data source named pulumi_stack_outputs that will fetch a Pulumi statefile, parse the outputs, and then supply them in Terraform as a native map(string) object.
In practice, it will often look something like this:
terraform { required_providers { pulumi = { version = "0.0.2" source = "hashicorp.com/transcend-io/pulumi" } } } provider "pulumi" {} data "pulumi_stack_outputs" "stack_outputs" { organization = "transcend-io" project = "airgap-telemetry-backend" stack = "dev" } output "stack_outputs" { value = data.pulumi_stack_outputs.stack_outputs.stack_outputs }
This code block tells Terraform to use the 0.0.2 version of the pulumi Terraform provider from transcend-io. It then declares the provider, where you can either supply a Pulumi cloud token directly, or via the PULUMI_ACCESS_TOKEN environment variable.
Lastly, it looks up the airgap-telemetry-backend/dev stack under the transcend-io organization and allows Terraform to consume that stack’s outputs. You’ll want to use your own organization, project, and stack names here, of course.
And with that, your Terraform modules can now depend on your Pulumi Cloud stacks.
Conclusion
One of Pulumi’s biggest strengths is that it has support for multiple programming languages that can be used together. If you have one Pulumi stack written in golang and another written in Typescript, one module could easily depend on the other via a StackReference.
With the tooling described in this post, you can essentially make Terraform one more language in your Pulumi toolchain if you’d like to. Or if you want to think of it as having many more languages in your Terraform toolchain, that’s cool too. Either way, the two tools can seamlessly work together in a way where it almost feels like they are all a part of one ecosystem.
At Transcend, this meant that we started by taking some of our more commonly updated Terraform modules that were painful to maintain and converted them over to Pulumi. This way, we could more easily manage things like multi-region deployments where Pulumi is easier to work with than Terraform.
As we did this though, we left the other Terraform files alone, as they can coexist and pose no real problems to us as a business. Just for ease-of-onboarding and consistency, we hope to eventually use one tool, though if some particular team ever decides they want to use golang, python, or HCL, we know it’ll be easy to support them.


By David Mattia