Automating the Future: The Rise of Data Mapping Automation Tools
13 min read


At a glance
- Automated data mapping is a software-driven process that connects data fields across different databases or datasets to streamline data integration, migration, and transformation.
- This technology increases data mapping efficiency and decreases human error, maximizing tight budgets and resources, while supporting strong business outcomes.
- Automated data mapping accurately and efficiently translates data between systems, enabling a wide range of applications including eCommerce integration, financial reporting, and privacy compliance.
Table of contents
- What is automated data mapping and why is it important?
- Key data management terms
- Automated data mapping for privacy
- Key components of automated data mapping
- The data mapping process step-by-step
- Methods for automating data mapping
- Scenario: Integrating data from multiple retail platforms
- Unlock automated data mapping with Transcend
- FAQs on automated data mapping
What is automated data mapping and why is it important?
Automated data mapping is a process that utilizes software to automatically connect data fields from one database or dataset to another.
At its core, it involves identifying relationships between data points across different systems and ensuring data seamlessly translates from one format or structure to another, without manual intervention.
This process is foundational for a variety of data operations, including data integration, migration, and transformation.
Purpose and benefits
The primary purpose of automated data mapping is to streamline the way data is handled, making it more efficient and reducing the risk of errors. It serves as the backbone for effective data management, enabling:
- Robust privacy compliance: Though data mapping tools have a wide variety of uses, they are a key part of ensuring compliance with modern privacy laws—helping companies understand what data they collect, where that data is stored, and how it's used.
- Seamless data integration: Automated mapping facilitates the consolidation of data from disparate sources, ensuring all information is harmoniously integrated into a central system.
- Efficient data migration: Whether upgrading systems or moving to the cloud, data mapping tools accelerate the movement of data throughout your data ecosystem, while preserving its integrity.
- Accurate data transformation: As data needs to be reformatted or cleansed, an effective data mapping tools ensures these transformations are carried out consistently and accurately.
In an era where data is increasingly recognized as one of the most valuable assets a company possesses, the significance of automated data mapping cannot be overstated.
For businesses, it not only helps to save time and resources, but also enhances data quality—providing a solid foundation for analytics and strategic decision-making. It democratizes data, making it accessible and usable across different departments, while supporting compliance with data protection regulations like the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA).
It's about empowering organizations to make better, data-informed decisions that drive growth and success. Whether you're a data professional, a business leader, or someone interested in the power of data, understanding and leveraging data mapping tools is a step toward unlocking the transformative potential of your data sources.
Key data management terms
A lot of the terms surrounding data management and data science are fairly new and can be a bit confusing. Here's a quick rundown of the most important terms you'll encounter as you start synthesizing large quantities of information.
Data source: The origin from which data is obtained. Data sources can be databases, spreadsheets, applications, or any system that generates, stores, or provides data.
Data maps: Diagrams or documents that show how data from one system corresponds to data in another system, detailing the relationships and transformation rules between different data fields.
Data pipelines: Automated processes designed to efficiently move and transform data from one stage to another within a data processing system or architecture, typically involving stages like collection, processing, storage, and analysis.
Data lakes: Large storage repositories that hold vast amounts of raw data in its native format until it is needed. Unlike data warehouses, data lakes store unstructured, semi-structured, and structured data, offering flexibility for data analysis and discovery.
Data transformation: The process of converting data from one format or structure to another. This can involve cleaning, aggregating, enriching, or reformatting data to make it suitable for analysis or to meet the requirements of a target system.
Data migration: The process of transferring data from one system or storage location to another. Data migration is often necessary during system upgrades, platform changes, or when consolidating data sources into a centralized location.
Automated data mapping for privacy
Data mapping plays a critical role in ensuring compliance with privacy laws. Here are three examples of how it can help:
- Identifying Personal Data: Data mapping can help identify where personal data is stored within an organization's systems. For instance, it can pinpoint the exact location of sensitive information like customer names, addresses, and credit card numbers. This is crucial for complying with privacy laws such as the General Data Protection Regulation (GDPR) which mandates that organizations must know where their personal data resides.
- Understanding Data Flow: Data mapping also helps in understanding how data moves within and outside the organization. It visualizes the journey of data from its entry point to its exit point, including all the processes it undergoes in between. This visibility is essential to ensure compliance with privacy laws, as it allows organizations to implement necessary controls at each stage of data processing.
- Risk Assessment: With a clear understanding of what data is held and how it's processed, organizations can better assess their privacy risks. Data mapping can help identify areas of potential non-compliance with privacy laws, such as unsecured data transfers or unnecessary data collection. This enables organizations to take corrective actions and mitigate risks, thus ensuring compliance with privacy laws.

Transform how companies discover where personal data is stored with the easiest way to uncover and catalog systems—no manual work required.
Explore Transcend Silo DiscoveryKey components of automated data mapping
Automated data mapping tools can accomplish a series of powerful data mapping tasks that work together to ensure data from various sources can be accurately mapped, transformed, and integrated into target systems.
Field matching
Field matching is the cornerstone of data mapping, involving the identification and linking of related fields between source and destination datasets.
This process relies on algorithms to automatically detect similarities in field names, data types, and patterns, enabling the accurate transfer of data between different systems.
Field matching can handle straightforward matches, such as connecting "First Name" in one database to "FirstName" in another, as well as more complex scenarios requiring semantic analysis to understand that "DOB" and "Birth Date" refer to the same information.
Schema recognition
Schema recognition involves understanding the structure and format of the data in both the source and target systems.
Automated data mapping tools analyze the schemas, which define the organization of data fields, their relationships, and data types, to ensure the mapping aligns with the structural constraints of the target system.
This component is crucial for maintaining data integrity and consistency, especially when integrating data from disparate sources with different schemas.
Transformation rules
Data rarely moves from source to target without the need for some form of transformation. Transformation rules define how data should be altered during the mapping process to fit the requirements of the target system or to meet specific business logic.
This can include converting data formats (e.g., changing dates from MM/DD/YYYY to DD-MM-YYYY), merging fields, splitting single fields into multiple ones, or applying formulas to calculate new values. Automated tools allow users to define these rules, which are then applied consistently across the data set.
Data validation and quality checks
One bad data apple spoils the whole bunch. Automated data mapping tools incorporate data validation and quality checks to identify and correct errors, inconsistencies, or missing information before the data is fully integrated into the target system.
This process includes verifying data accuracy, completeness, and conformity to specific standards or requirements. By embedding quality checks into the mapping process, these tools help maintain high data integrity and reliability.
Additional considerations
Beyond these core components, several other aspects enhance the functionality and effectiveness of automated data mapping tools:
- Metadata management: Utilizing metadata, or data about data, to inform and optimize the mapping process. Metadata can provide insights into data lineage, usage, and governance, aiding in more informed mapping decisions.
- User interface and usability: Offering an intuitive graphical user interface (GUI) that allows users to easily configure mappings, define transformation rules, and review validation results, making the process accessible to users with varying levels of technical expertise.
- Integration capabilities: Providing robust integration options with a wide range of data sources, databases, and applications, ensuring the mapping tool can function effectively within the organization's existing data ecosystem.

The data mapping process step-by-step
The data mapping process is fundamental to ensuring data flows accurately and efficiently from source systems to target systems, undergoing necessary transformations along the way. Here's a step-by-step breakdown of how it usually works:
Step 1: Define source and target data structures
- Identification: Begin by identifying the data structures of both the source and target. This involves understanding the schema, format, and content of the datasets you're working with.
- Analysis: Analyze the data types, relationships, and constraints within each structure to prepare for accurate mapping.
Step 2: Establish mapping rules
- Field matching: Determine how fields in the source dataset correspond to fields in the target dataset. This may involve direct matches (e.g., “Customer ID” to “Client ID”) or require transformations.
- Transformation definition: Define any necessary transformation rules for converting data formats, merging fields, or applying business logic to the data as it moves from source to target.
Step 3: Implement data validation criteria
- Quality checks: Set up criteria for validating the data’s accuracy, completeness, and consistency. This might include checks for missing values, data type verification, and integrity constraints.
- Error handling: Define how errors will be identified, logged, and addressed. Decide whether erroneous data should be corrected automatically, flagged for review, or rejected.
Step 4: Execute the initial mapping
- Trial run: Use your data mapping tool to perform an initial mapping based on the defined rules and validation criteria. This step often involves a subset of the data to test the accuracy of the mapping.
- Review results: Analyze the outcome of the trial run, focusing on the accuracy of field matches, the success of data transformations, and the identification of any data quality issues.
Step 5: Refine and optimize mapping
- Adjustments: Based on the results of the initial mapping, make necessary adjustments to mapping rules, transformation logic, or validation criteria to improve accuracy and efficiency.
- Iterative testing: Repeat the mapping process with these adjustments, iterating until the data is accurately mapped and meets quality standards.
Step 6: Full-scale execution
- Deploy mapping: Once satisfied with the mapping configuration, execute the mapping process at full scale, processing the complete dataset.
- Monitor process: Closely monitor the mapping for any unexpected issues or errors, ensuring data is correctly processed and integrated into the target system.
Step 7: Continuous monitoring and maintenance
- Regular reviews: Establish a schedule for regularly reviewing and updating mapping configurations to accommodate changes in source or target data structures or to refine transformation logic.
- Adaptation to changes: Stay agile to adapt mappings for new data sources, changes in business requirements, or updates in compliance regulations.
Step 8: Documentation and governance
- Documentation: Thoroughly document the mapping process, including source and target structures, mapping rules, transformation logic, and validation criteria, for future reference and compliance audits.
- Data governance: Integrate the mapping process into broader data governance frameworks to ensure ongoing data quality, security, and compliance.

Methods for automating data mapping
Automating the data mapping process involves several methodologies, each with its unique approach to solving the puzzle of how to efficiently and accurately translate data from one system to another. Here's an overview of the primary methods used in automated data mapping:
Rule-based mapping
This method employs predefined rules to map data fields between sources and targets. Rules can be based on field names, data types, or specific patterns, making it a straightforward approach for scenarios where the relationships between data elements are well-understood and consistent.
Schema-based mapping
Schema-based mapping relies on the structure of the data itself, utilizing the database schema (the formal definition of how data is organized in a database) to guide the mapping process. It's particularly useful for structured data where the schema can be easily interpreted by the mapping tool.
Semantic mapping
Semantic mapping goes beyond simple structural matches, focusing on the meaning and context of the data. By understanding the semantics, or the "meaning," behind data elements, it can link fields that are conceptually related but not obviously so, enhancing the depth and relevance of the mapping.
Metadata-based mapping
This technique leverages metadata—data about data, such as column names, data types, and descriptions—to inform the mapping process. Metadata-based mapping is adept at handling large datasets across diverse systems, providing a high-level understanding that guides the mapping.
Hybrid mapping
Hybrid mapping combines two or more of the above methods to take advantage of their respective strengths. By blending approaches, hybrid mapping can tackle a wide range of data scenarios, from straightforward to highly complex.
Pattern recognition mapping
Utilizing algorithms to detect patterns within the data, this method can automate the mapping of similar data structures or fields across different systems. It's especially useful for unstructured or semi-structured data where traditional mapping methods may fall short.
Cognitive mapping
Incorporating advanced AI techniques, cognitive mapping interprets the intent and nuanced meanings behind data. It can process natural language and even images or videos to extract and map data based on its cognitive understanding, ideal for complex or unstructured data sources.
Probabilistic mapping
Probabilistic mapping uses statistical models to determine the likelihood of matches between data fields, offering a range of potential mappings ranked by probability. This method is valuable in uncertain environments, where direct matches are not clear, and decisions need to be made on the best available match.
Anchor-based mapping
Anchor-based mapping identifies key data points or "anchors" that are consistent across different data sets to serve as reference points for the mapping. These anchors help to align the rest of the data, ensuring coherence and reliability in the mapped output.
Each of these methods offers unique advantages and can be selected based on the specific requirements, complexity, and goals of the data mapping project.
The choice of method often depends on the nature of the data, the desired level of automation, and the specific challenges presented by the data integration task at hand.

Scenario: Integrating data from multiple retail platforms
Imagine a scenario where a retail company sells products across various online platforms, including Amazon, eBay, Shopify, and its proprietary eCommerce site.
Each platform has its unique data structure, naming conventions, and formats for representing product information, sales data, customer interactions, and inventory levels.
The challenge lies in consolidating this disparate data into a single, cohesive system for unified analytics, inventory management, and customer service.
Solution through automated data Mapping:
- Data Analysis: The first step involves analyzing the data structures of each platform to understand the schemas and identify corresponding fields. For instance, product identifiers might be listed as "ASIN" on Amazon and "ItemID" on eBay.
- Field Matching Techniques: Using automated data mapping, the company employs field matching techniques to correlate these identifiers, aligning "ASIN" with "ItemID" across datasets. Machine-learning-based mapping can further refine these matches by learning from mapping decisions and improving accuracy over time.
- Schema Recognition: Automated tools recognize and adapt to the different schemas of each platform, ensuring that product descriptions, pricing information, and inventory counts are accurately mapped to the unified system's schema.
- Transformation Rules: The company sets up transformation rules within the mapping tool to standardize date formats, currency, and measurement units, making the data consistent and comparable across platforms.
- Data Validation: Before final integration, automated validation checks ensure the accuracy and integrity of the mapped data, flagging discrepancies for review.
- Unified Analytics and Reporting: With data successfully integrated, the company can now perform unified analytics, gaining insights into sales trends, inventory needs, and customer preferences across all platforms.
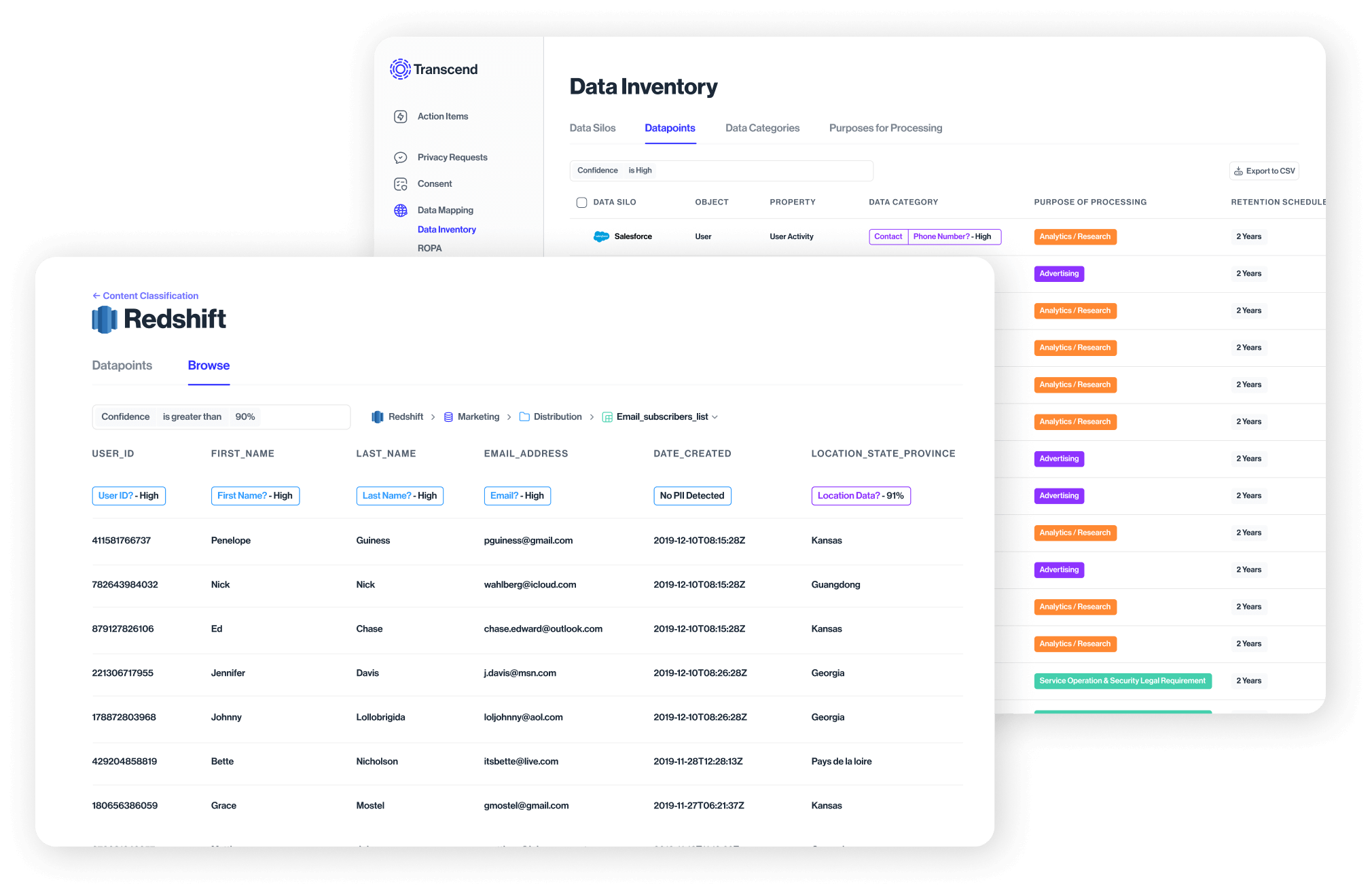
Unlock automated data mapping with Transcend
The best data mapping tools not only help you integrate data across multiple data formats, but also help you keep that data safe, secure, and GDPR-compliant.
That's why we've built our automated data mapping tool: to help you simplify data mapping without compromising on user experience or data privacy.
Transcend suite of data mapping tools goes beyond traditional data mapping capabilities, enabling smarter governance of your company's data landscape. Use:
- Transcend Data Inventory to gain a single source of truth of all personal data moving through your organization. Get powerful 360-degree visibility that powers seamless real-time privacy operations.
- Transcend Silo Discovery to transform how your company discovers where their personal data is stored. It's the easiest way to uncover and catalog systems—no manual work required.
- Transcend Structured Discovery to identify and classify data down to the datapoint level, all without manual work or traditional heavy deployments.
- Transcend Unstructured Discovery to automatically find and govern previously ungovernable data, for complete compliance.
Whether your data resides in databases like Snowflake and Salesforce or non-conventional models such as documents and chat apps, Transcend ensures comprehensive governance.
Say goodbye to the cumbersome process of manual spreadsheets and constant follow-ups for updates. Transcend automates data silo discovery and classification, saving you time and resources.
Empower your organization with Transcend's automated data mapping tool, where security, efficiency, and compliance converge to facilitate smarter data governance. Get a demo and start transforming your organization's data management today.
FAQs on automated data mapping
What's the difference an automated data mapping tool and a data integration tool?
Data integration tools consolidate and transform data from multiple sources into a unified system for analysis, handling data extraction, transformation, and loading processes.
Automated data mapping tools focus on linking related data fields across different datasets, automating the mapping process to ensure accurate data correspondence.
The key difference lies in their data mapping processes: data integration tools provide a comprehensive solution for managing data workflows, while automated data mapping tools specifically address the task of establishing field relationships within the broader integration process.
What is automated data mapping, and how does it differ from manual data mapping?
Automated data mapping utilizes software to create connections between data fields across different systems automatically, significantly speeding up the process and reducing errors compared to manual data mapping.
Manual mapping requires human intervention to establish these connections, making it more time-consuming and prone to inaccuracies.
How do data integration tools facilitate automated data mapping?
Data integration tools are designed with advanced data mapping capabilities that automate the process of combining data from disparate sources into a cohesive and unified view.
These tools use algorithms and AI to recognize patterns, match fields, and transform data, streamlining the integration process for databases, data warehouses, and other systems.
How does automated data mapping support the creation and maintenance of a data warehouse?
Automated data mapping is crucial for populating and updating a data warehouse, as it enables the efficient transformation and transfer of data from various sources into the warehouse's schema.
This ensures that the data warehouse remains accurate, up-to-date, and reflective of the organization's operational data for analytics and reporting purposes.
Can automated data mapping software handle complex transformations required for data analysis?
Yes, modern data mapping software is equipped with powerful transformation capabilities that allow for complex data manipulations, including aggregations, calculations, and format changes.
These transformations are essential for preparing data for analysis, ensuring it's in the right structure and format for data scientists and analysts to derive insights.
What features should I look for in data mapping software to ensure it meets my organization's needs?
When selecting data mapping software, consider features such as support for a wide range of data sources and formats, intuitive mapping interfaces, robust transformation capabilities, scalability to handle large volumes of data, and strong security measures to protect sensitive information.
Additionally, look for software that offers flexibility in handling both batch and real-time data integration scenarios.
Discover Transcend's data mapping solutions
Transcend's suite of next-generation data mapping solutions gives your organization the visibility you need to transform data governance initiatives, power strategic decision making, and ensure a robust compliance stance.
- Transcend Data Inventory to gain a single source of truth of all personal data moving through your organization. Get powerful 360-degree visibility that powers seamless real-time privacy operations.
- Transcend Silo Discovery to transform how your company discovers where their personal data is stored. It's the easiest way to uncover and catalog systems—no manual work required.
- Transcend Structured Discovery to identify and classify data down to the datapoint level, all without manual work or traditional heavy deployments.
- Transcend Unstructured Discovery to automatically find and govern previously ungovernable data, for complete compliance.
Transcend Data Inventory provides your foundation for base truth, and can be used in tandem with any combination of discovery solutions. Reach out to learn more.


Senior Marketing Manager II, Strategic Accounts