Mastering Data Mapping: Techniques and Best Practices for Optimal Integration
11 min read


At a glance
- What is data mapping? If you’ve landed on this page, you might be looking to answer that question. Lucky you—this guide is here to help!
- Data mapping is the process of matching data fields in one database to corresponding data fields in another—helping the two databases communicate and share data more effectively.
- Data mapping has many applications, but is commonly used for data integration, transformation, or migration. It’s also a foundational part of complying with modern privacy laws such as the General Data Protection Regulation (GDPR) and California Consumer Protection Act (CCPA).
- You can use a data mapping template to manually create a data map (we’ll cover those steps, plus best practices below). However, if you’re dealing with large data sets or multiple systems, using an automated tool is recommended.
Table of Contents
- Data mapping definition
- What’s the purpose of data mapping?
- Data mapping techniques
- How to create a data mapping template
- 5 steps for a manual data mapping process
- Data mapping best practices
- The role of data mapping in data privacy and compliance
- Choosing the right data mapping tool
- The future of data mapping
Data mapping definition
Data mapping is the process of matching data fields in one database to corresponding data fields in another—helping the two databases communicate and share data more effectively.
Imagine a customer profile for Jane Elliot appears in two different databases, but the data analyst wants her profile counted only once. Through a series of data mapping steps, the analyst can create a connection between the two Jane Elliot’s, ensuring she doesn’t get counted twice in an analysis or query.
Though this example of data mapping is fairly simple, it is reflective of data mapping’s basic purpose: building connections to improve data quality, standardize data across different systems, and support better analysis down the line.
In 2020, mid-size companies were using an average of 288 different software-as-a-service (SaaS) apps, according to a 2020 SaaS Trends report.
That’s why for most large-scale applications, using automated data mapping is recommended.
It is theoretically possible to use a data mapping template or other manual means to create a full data map, but that exercise would get complicated quickly.
Imagine trying to constantly translate between 288 different languages, with thousands of people speaking all at once (!!!), and you don’t have any tools or automatic processes backing you up. Overwhelming at best, impossible at worst.
That’s why employing a good data mapping software, which enables a crucial level of process automation, is recommended in most cases. All of that said, your purpose or end goal will ultimately define what tool you’ll actually need.
What’s the purpose of data mapping?
The overarching goal of data mapping is to bring more structure and cohesion to your company’s data.
In a more focused context, such as data privacy, the data mapping process is foundational to complying with modern privacy laws like the General Data Protection Regulation (GDPR) and the California Privacy Rights Act (CPRA).
By creating and maintaining a unified data inventory, including the flow and structure between different databases, systems, and SaaS tools, a company can:
- Track down data for data subject access requests (DSAR) i.e. when a consumer asks to see all the data a company has collected about them.
- Identify risky data processing activities, which under GDPR Article 35 requires completing a data protection impact assessment.
- Create and maintain records of processing activities, as required by GDPR Article 30.
However, data maps do have a wide range of applications outside of data privacy compliance. Companies can use data mapping to improve data accuracy, better integrate data into a data warehouse, provide valuable insights on complex data, and enable better data analysis.
Remember, data mapping helps different data systems communicate, passing data back and forth in a shared language created through the data mapping process. In practical terms, this process of built understanding can take many forms; however, the most common applications for data mapping include data transformation, migration, and integration.

Data transformation
Data transformation is the process of translating data between different formats, usually from an unstructured data type (like text or media files) into a more usable format (like CSV). Often referred to as extract/transform/load (ETL), this process often involves some degree of data cleaning, validation, or enrichment.
Data migration
Data migration, moving data from one location to another, is simple in principle, but often complex in practice. The complexity stems from the fact that moving data between locations often involves a change in data format. Examples of data migration include moving from an on-premise data center to the cloud, moving data between hardware systems, combining data systems, and migrating data to a new software or SaaS tool.
Data integration
Data integration is the act of unifying different data sources into one central location—with the primary goal of enabling sound analysis for informed decision making.
This process usually involves some degree of data transformation, as creating a unified view of data often requires data cleaning, duplicate removal, and/or putting all data into a cohesive, shared format.
Keep in mind that, though these data mapping use cases are defined individually, they have a lot of overlap when actually applied. Effective data migration requires some level of data integration and, as mentioned, effective data integration often requires some degree of transformation.

Data mapping techniques
Manual data mapping
- The good: Fully customizable
- The bad: Time and resource intensive, relies entirely on code, often requires advanced skills and specialized knowledge
Creating data maps manually means using code (and a talented developer) to connect the data fields between different sources. The process often involves using ETL functions or other coding languages like C++, SQL, or Java.
Though this approach gives the data mapper ultimate control over the process and final product, it can be quite unwieldy given the quantity of data and data systems used by most businesses. Manual data mapping is really only a good option for smaller databases or one-time processes.
Semi-automated data mapping
- The good: Balances scalability, efficiency, and flexibility
- The bad: Manual parts of the process can be time and resource intensive, requires coding knowledge and an understanding of how to navigate between the automated and manual components
Sometimes called schema mapping, semi-automated data mapping blends automation processes with manual intervention. In this data mapping approach, a developer will use software to define relationships between data fields that are similar, but not the same—eventually creating schemas.
For example, they might match ‘Social’ with ‘SSN,’ or ‘FirstName’ with ‘FName’ and ‘first_name.’ Depending on the tool they’re using, there are various methods to complete this process including drag-and-drop, drawing lines, or smart clustering.
After defining the schemas, a script or other code is run to complete the actual data conversion. This portion of the process usually requires coding knowledge, as the script is generally built with C#, Java, or C++.
Automated data mapping
- The good: Faster outcomes, least coding knowledge required
- The bad: Some automated tools can be costly and often require platform-specific training
Automated data mapping removes the need for code, allowing more people to engage with and update a company’s data map. Depending on the solution, automated data mapping allows for drag-and-drop mapping, pre-built transformations, and even representations of data flow.
Because automated platforms don’t require coding knowledge, your no-code team members can manipulate the data as necessary and steward their own analysis without making constant requests to your data analysts.
Though these tools have their own challenges, the time saved combined with the lower barrier to entry for non-technical folks make it a worthwhile investment for many companies.
The benefits of automated data mapping tools
- Efficiency and Speed: Automated tools can process vast amounts of data much faster than a human could manually, saving significant time and resources.
- Accuracy: Automated tools are less prone to human error, ensuring that the data maps they generate are precise and reliable.
- Consistency: With an automated tool, data mapping rules can be standardized across the organization, resulting in consistent and predictable outcomes.
- Compliance: Many automated tools include features that check for compliance with data privacy regulations, reducing the risk of non-compliance penalties.
- Integration: Dedicated tools often include integration capabilities, allowing them to work seamlessly with a variety of data sources and types.
In essence, by using an automated tool, organizations can streamline and enhance their data management processes, resulting in improved data quality, greater operational efficiency, and better decision-making capabilities.
How to create a data mapping template
Reading about data mapping isn’t necessarily the best way to understand the concept. That’s why we included a few things to consider when creating your own data mapping template.
While you’re creating your template, keep in mind its potential long-term use and document accordingly. Include data management policies—guidelines for tracking data lifecycle across ingestion, transformation, analysis, etc— within your template, as this will help both you and your team maintain a healthy data map in the future.
This in mind, your template should include:
- Name of the source database (Where the data is coming from)
- Name of the target database (Where the data is going)
- Which columns or values you’re mapping
- The intended format for the data post-transformation
- Triggers for the data integration or transfer
- Documentation on any automation (when and how it will run, intended outcome, possible failure points)
When working with data at scale, using an automated data mapping solution or platform is still recommended. However, creating your own template can be a great starting point if you’re looking to get a better grasp of the concept, create a data management framework for your team, or map smaller quantities of data.
5 steps for a manual data mapping process
Though the process itself is more involved in practice, there are five basic data mapping steps.
1. Determine which data fields to include in your map
What you’re trying to achieve with your data map will be the best guide for deciding what data fields need to be included. Questions you might ask include:
- What data needs to be combined?
- How many data sources are there?
- How often will this process need to be repeated?
- What is your target location?
- What format(s) need to be accounted for?
2. Determine standard naming conventions
Once you’ve determined which data fields you plan to map, identify and document the data formats for each. Then, determine the target data format. For instance, if you’re integrating a list of clients and your source data has a ‘First Last’ format, but your target database takes a ‘Last, First’ format—you’ll need to identify this upfront so as to set conditions for the data’s final format.
3. Define schema logic or transformation rules
How this step plays out relies almost entirely on your data mapping approach. If you’re mapping data manually, these rules will be created by the developer writing the code. For semi-automated, you’ll be defining the schema and data connections and a developer might create code for any transformations. With automated platforms, the software will do much of the work for you.
4. Test the logic on a small sample
Before you go all in, it’s a good idea to test your logic on a smaller data set to ensure everything is working the way you intended. Errors in your logic or transformation rules could create errors or other issues in the final data map, or the dataset itself. Especially if you’re dealing with a particularly large dataset, it never hurts to err on the side of caution—measure twice, cut once isn’t just for DIY.
5. It’s go time—complete your data map
Once you’ve defined your data field, determined naming conventions, defined your logic or rules, and then checked for bugs, you’re ready to go. Migrate, integrate, or transform your data to your heart’s delight.

Data mapping best practices
Though automation can do most of the heavy lifting, even someone using the best data mapping software available, should consider evangelizing data mapping best practices throughout their organization. Working towards standard operating procedures and strict data hygiene will make your day-to-day work easier and benefit your organization in the long term.
Document, document, document
Though it can feel tedious to document your tools and procedures, it will pay significant dividends in the long run. Small changes in a tool’s configuration, how a data field is named, or an updated automation schedule can cause big issues if everyone isn’t on the same page. Document your tools and processes and make sure to regularly socialize any changes with relevant teams.
Standardize naming conventions
Number 2 has some overlap with Number 1, admittedly, but it’s important enough to merit its own callout. Create a readily accessible document outlining a clear approach to naming conventions and remind people of its existence whenever you can. The ideal is that eventually these conventions become rote, but it never hurts to have a universal reference point.
Shore up data security
As high-profile data breaches continue to make headlines, ensuring data security is a best practice for any organization—regardless of the data mapping activities you engage in. That said, data integration in particular—as it pulls data from multiple sources into a single master location and often involves a greater level of access for more people—can create vulnerabilities.
Taking a least privilege approach, limiting access to only those that need it, only to the level they need it, is a best practice no matter the context. For a stronger security stance, the context will define the specifics, but strategies to consider include data encryption, tokenization, or masking.
Conduct regular maintenance
Data mapping, like any machine with many moving parts, requires regularly scheduled maintenance. This maintenance can take the form of debugging, simplifying your automation, or making code tweaks to better suit your business needs.
As a dynamic, ongoing process, data integration in particular can require regular updates to ensure everything runs as it should. Data sources can undergo changes that disrupt the defined mapping paths, so it’s critical that the data administrator monitor the system in order to identify and repair any broken pathways.
Depending on the size of the system in question, this process can become time consuming—quickly overwhelming a single person or even an entire team. This brings us to our final best practice: automation.
Automate what you can
At a very small scale, automating your data mapping may not be necessary. It is possible to complete many data mapping tasks without it. However, as the number of fields, systems, and databases grow, so does the need for automation.
Past a certain size and level of complexity, data mapping tools like spreadsheets simply won’t work. Beyond pure efficacy, automated data mapping provides other significant benefits: eliminating manual errors, saving you or your team hours or even days of work, and as a result, speeding up the process overall.
As we covered in earlier sections though, automation doesn’t need to be an all or nothing exercise. For data mapping, automation occurs on a spectrum, so if you don’t have the resources or need for a fully automated tool right now, explore options that would allow you to automate parts of the process (ideally those that are taking you the most time).
Any level of automation should save you time in the end, so if data mapping is something you do on a regular basis it’s definitely worth exploring.

Data mapping and data privacy compliance
Data mapping under the GDPR and CPRA
Data mapping plays a crucial role in ensuring compliance with data privacy regulations such as the General Data Protection Regulation (GDPR) and the California Privacy Rights Act (CPRA). To comply with these regulations, organizations need to have a clear understanding of the personal data they hold, its source, how it's processed, and where it is stored or transferred.
Under GDPR specifically, organizations are required to maintain a record of processing activities (ROPA). Data mapping aids in this process by tracing the flow of personal data through the organization, providing the insights necessary to build a thorough ROPA document.
Data mapping and data subject access requests
Data mapping also plays a critical role in managing data subject access requests (DSARs), a cornerstone requirement of most modern privacy laws. DSARs are requests from individuals to access their personal data held by an organization.
To efficiently respond to DSARs, companies need a solid understanding of where the personal data resides, which can be achieved through data mapping. It allows the organization to swiftly locate and retrieve the required information, ensuring timely and accurate responses to DSARs.
Choosing the right data mapping tool
When choosing a data mapping tool, there are several essential features to consider that will help you get the most value out of your investment.
1. User-friendly visual interface
A clean, intuitive user interface is indispensable. This makes it easier for users to navigate the tool, identify data patterns, and track map customer data without the need for extensive technical knowledge.
2. Automation capabilities
Look for a tool with strong automation features. Automated data mapping can dramatically speed up processes, reduce manual errors, and free up your team's time for more valuable tasks.
3. Diverse integration options
The ability to integrate with various data sources, data models, data sets, databases, data warehouses and data types is crucial. This ensures your tool is flexible and can support your data mapping needs as your organization and data management tasks evolve.
4. Scalability
Consider the scalability of the tool. As your data grows in complexity and volume, it is essential that your data mapping tool can scale alongside and handle increased demand without any compromises on performance.
5. Security features
Given the sensitive nature of data handling, robust security features are non-negotiable. These may include encryption, access control, and compliance with data privacy regulations.
6. Support for metadata management
Metadata management is a valuable feature that allows you to keep track of all information about your data, making data mapping and data governance processes more efficient.
7. Version control and change management
Version control and change management features enable you to track changes made to your data maps over time. This can be crucial for auditing purposes, debugging, and ensuring consistency in data understanding and usage.
By considering these features in your selection process, you can ensure that you choose a data mapping tool that fits your organization's specific needs and facilitates efficient, reliable, and secure data mapping processes.

Get our step-by-step guide to evaluating the right data mapping solution for your business.
Get the guideThe future of data mapping
As we move forward, the future of data mapping is set to be influenced by several key trends. Technological advancements are taking center stage, pushing the boundaries of what's possible in data mapping.
Increased automation
Automation in data mapping is expected to intensify. As the volume of data increases and becomes more complex, the need for automated solutions is more pronounced than ever. Automation can efficiently handle large datasets, eliminating manual errors and significantly reducing the time taken to map data.
Advanced capabilities
The capabilities of data mapping software are expected to advance considerably. Future tools will likely have capabilities to handle more complex data structures, including multi-dimensional databases. They will also offer even more robust integration features, supporting a wide array of data sources and types for maximum flexibility.
Machine learning and AI
Machine Learning (ML) and Artificial Intelligence (AI) are expected to play a crucial role in the future of data mapping. These technologies can learn from and make predictions based on data, which can be beneficial in identifying patterns and trends in the data. This makes them highly effective at automating and optimizing the data mapping process.
These trends highlight an exciting future for data mapping, with technology driving significant enhancements in efficiency, accuracy, flexibility, and security.
Conclusion
Data mapping stands as a pivotal element in the realm of efficient data management and compliance. It forms the backbone of an organization's data governance framework, promoting transparency, accuracy, and accountability.
Discover Transcend's data mapping solutions
Transcend's suite of next-generation data mapping solutions gives your organization the visibility you need to transform data governance initiatives, power strategic decision making, and ensure a robust compliance stance.
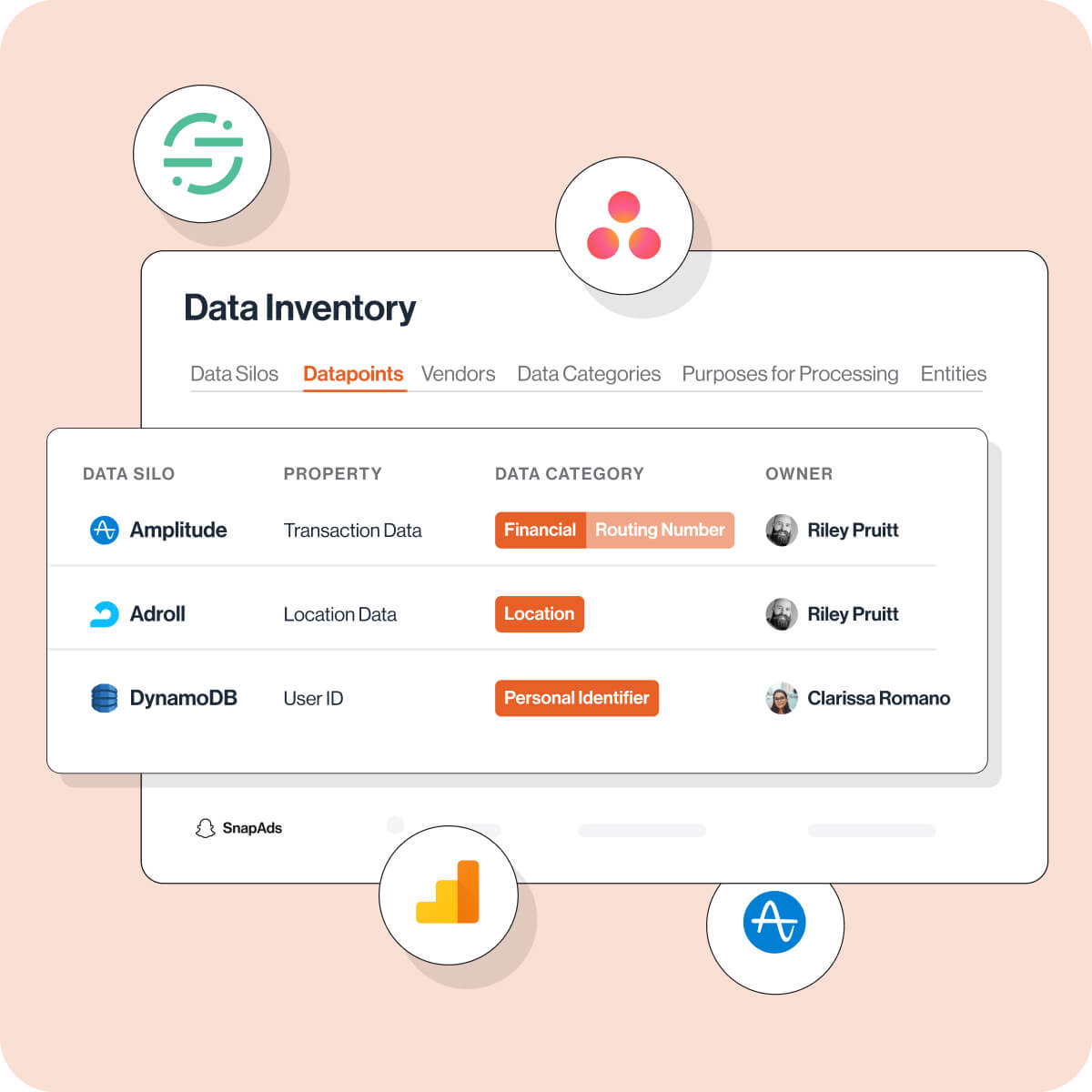
- Transcend Data Inventory to gain a single source of truth of all personal data moving through your organization. Get powerful 360-degree visibility that powers seamless real-time privacy operations.
- Transcend Silo Discovery to transform how your company discovers where their personal data is stored. It's the easiest way to uncover and catalog systems—no manual work required.
- Transcend Structured Discovery to identify and classify data down to the datapoint level, all without manual work or traditional heavy deployments.
- Transcend Unstructured Discovery to automatically find and govern previously ungovernable data, for complete compliance.
Transcend Data Inventory provides your foundation for base truth, and can be used in tandem with any combination of discovery solutions. Reach out to learn more.


Senior Marketing Manager II, Strategic Accounts