The Genesis of CLI Terraform Provider: Bridging Efficiency and Flexibility
12 min read


From a leaked internal document at Facebook, we see the clear struggle with governing personal data:
We do not have an adequate level of control and explainability over how our systems use data, and thus we can’t confidently make controlled policy changes or external commitments such as “we will not use X data for Y purpose.” And yet, this is exactly what regulators expect us to do, increasing our risk of mistakes and misrepresentation.
As Facebook continues with years of legal proceedings stemming from their use of personal data, it becomes increasingly important for all companies to be able to accurately identify and govern all personal data in their systems.
At Transcend, we’ve recently open sourced two infrastructure as code tools that make both identification and governance of personal data in your engineering systems much easier.
About the new tools
The Transcend Terraform Provider
We recently announced the release of our official Terraform Provider. This provider lets you declaratively create and update:
- Data silos (integrations with third parties like Stripe/Datadog/Salesforce or internal databases),
- Datapoints (classifications of a set of personal data that exists under some data silo),
- API keys (that can be scoped to individual data silos if needed),
- Enrichers (a concept for connecting user identifiers like phone numbers, user IDs, and email addresses)
- And more!
One of the great things about the Terraform provider is that it allows you to integrate Transcend alongside any other tools that have Terraform providers.
Here’s an example of a snippet that creates an IAM Role in an AWS account—giving Transcend access to scan an account for what personal data it might contain and then using the Transcend provider to create and connect an AWS data silo.
resource "transcend_data_silo" "aws" { type = "amazonWebServices" description = "Amazon Web Services (AWS) provides information technology infrastructure services to businesses in the form of web services." # Normally, Data Silos are connected in this resource. But for AWS, we want to delay connecting until after # we create the IAM Role, which must use the `aws_external_id` output from this resource. So instead, we set # `skip_connecting` to `true` here and use a `transcend_data_silo_connection` resource below skip_connecting = true lifecycle { ignore_changes = [plaintext_context] } } resource "aws_iam_role" "iam_role" { name = "TranscendAWSIntegrationRole2" description = "Policy to allow Transcend access to this AWS Account" assume_role_policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = "sts:AssumeRole" Effect = "Allow" // 829095311197 is the AWS Organization for Transcend that will try to assume role into your organization Principal = { AWS = "arn:aws:iam::829095311197:root" } Condition = { StringEquals = { "sts:ExternalId" : transcend_data_silo.aws.aws_external_id } } }, ] }) inline_policy { name = "TranscendPermissions" policy = jsonencode({ Version = "2012-10-17" Statement = [ { Action = [ "dynamodb:ListTables", "dynamodb:DescribeTable", "rds:DescribeDBInstances", "s3:ListAllMyBuckets" ] Effect = "Allow" Resource = "*" }, ] }) } } # Give AWS Time to become consistent with the new IAM Role permissions resource "time_sleep" "pause" { depends_on = [aws_iam_role.iam_role] create_duration = "10s" } data "aws_caller_identity" "current" {} resource "transcend_data_silo_connection" "connection" { data_silo_id = transcend_data_silo.aws.id plaintext_context { name = "role" value = aws_iam_role.iam_role.name } plaintext_context { name = "accountId" value = data.aws_caller_identity.current.account_id } depends_on = [time_sleep.pause] }
This can enable all sorts of cool integrations like connecting Transcend and Datadog to remove logs relating to a particular user, securely connecting with clouds like AWS, Google Cloud, or Azure, or creating a database and then immediately connecting it to Transcend.
The CLI tool
Our second infrastructure as code tool is the `@transcend-io/cli` NPM package that can be used as a standalone binary.
Similar to the Terraform provider, the Command Line Interface (CLI) is an infrastructure as code tool aimed at making discovering and governing data easier. The schema is very similar to the Terraform API, but has three major reasons why you might want to use it:
- If your organization does not have established practices around Terraform and how to deploy it on CI, the CLI provides a lower barrier of entry.
- If you are planning on auto-generating the config to upload to Transcend (which we’ll show an example of later), then it may be more natural to output YAML (which the CLI injests) than HCL from Terraform.
- The CLI comes with options for generating configuration from your existing Transcend account that are not present in the Terraform provider. The Terraform provider would require using `terraform import` to bring already existing infrastructure into your code.
You are also welcome to use both tools in conjunction with one another. We have seen success when using Terraform to manually configure systems and to securely specify API credentials while using the CLI to upload auto-generated datapoint schemas. But feel free to use whichever tool or combination fits your business needs best.
Data Mapping with Transcend
You can’t manage what you can’t see, so step one in setting up a privacy program is often determining where personal data lives inside your systems. If, like at most companies, the personal data you collect changes over time, data mapping is not an exercise you can complete once and then forget about.
Robust data mapping systems must enable you to retroactively find personal data in your legacy and existing systems, proactively manage new sources of personal data as you add them, and continuously scan for personal data to prevent missing personal data that may be added in the future.
Retroactively finding and classifying personal data
At Transcend, we understand that not every software project starts out designing for privacy. Companies that have been around for a while likely have systems containing personal data that predate the current laws and regulations around how personal data must be handled. And as new laws come into effect in the future, those systems may need updates again.
It’s often infeasible to ask a company to go back and hand label where all of their personal data lives.
- Did the person who created a central system leave your company and nobody is quite sure how “that server over there” works or what data it contains?
- Do you have thousands of databases with millions of tables and tens of engineers?
- Is there a disconnect between the people you want to be responsible for labeling data (such as legal) and the people who know how to find that data (such as engineers)?
Enter our Data Silo Plugins. These come in a variety of forms to help you sort through your old systems.
Silo Discovery Plugins
We have Silo Discovery Plugins that can find and suggest data silos your org uses. Examples include scanning an AWS account for databases used, your SSO tool such as Okta for all applications your employees can access, or Salesforce for where you might keep personal data on prospects and leads.
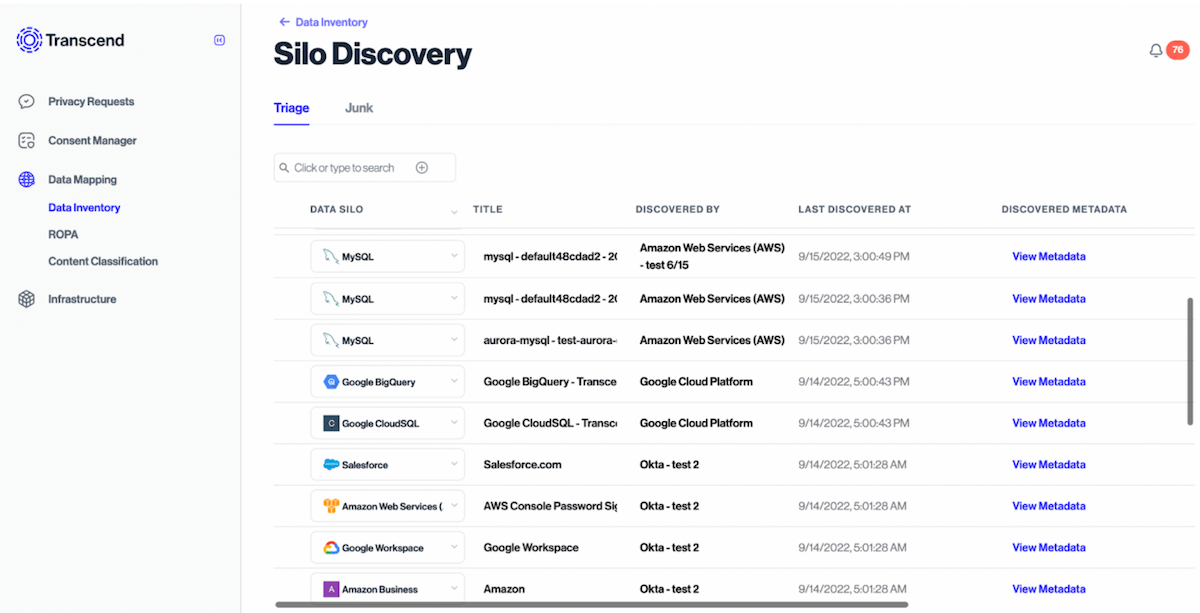
Using our Terraform provider, adding a data silo plugin is as easy as defining when you want the scans to start and how often you want them to occur going forward.
resource "transcend_data_silo" "aws" { type = "amazonWebServices" description = "Amazon Web Services (AWS) provides information technology infrastructure services to businesses in the form of web services." plugin_configuration { enabled = true type = "DATA_SILO_DISCOVERY" schedule_frequency_minutes = 1440 # 1 day schedule_start_at = "2022-09-06T17:51:13.000Z" schedule_now = false } # ...other fields... } # ...other resources...
In this example, we set up an AWS data silo to scan for databases, S3 buckets, and other resources that often contain personal data.
Silo Discovery via dependency files
Another way to discover data silos to connect is by scanning your codebase for external SDKs. Transcend can then map those SDKs to data silos and suggest them to you to add. Currently we support scanning for new data silos in Javascript, Python, Gradle, and CocoaPods projects.
To get started, you'll need to add a data silo for the corresponding project type with the Silo Discovery Plugin enabled. For example, if you want to scan a JavaScript project, add a “JavaScript package.json” data silo. You can do this in the Transcend admin-dashboard (or via this CLI tooling or Terraform).
Then, you'll need to grab that dataSiloId and a Transcend API key and pass it to the CLI. Using JavaScript package.json as an example:
# Scan a javascript project (package.json files) to look for new data silos yarn tr-discover-silos --scanPath=./myJavascriptProject --auth={{api_key}} --dataSiloId={{dataSiloId}}
This call will look for all the package.json files that are in the scan path ./myJavascriptProject, parse each of the dependencies into their individual package names, and send it to our Transcend backend for classification.
These classifications can then be viewed in the data silo recommendations triage tab, just like where you’d look with other Silo Discovery mechanisms. The process is the same for scanning requirements.txt, podfiles and build.gradle files.
Datapoint Discovery Plugins
We also have Datapoint Discovery Plugins that can go into your data stores and extract your schemas. This supports databases like BigQuery, MongoDB, DynamoDB, Snowflake, PostgreSQL, MySQL, Redshift, and many more, while also supporting data stores such as Google Forms, Amazon S3, and Salesforce.
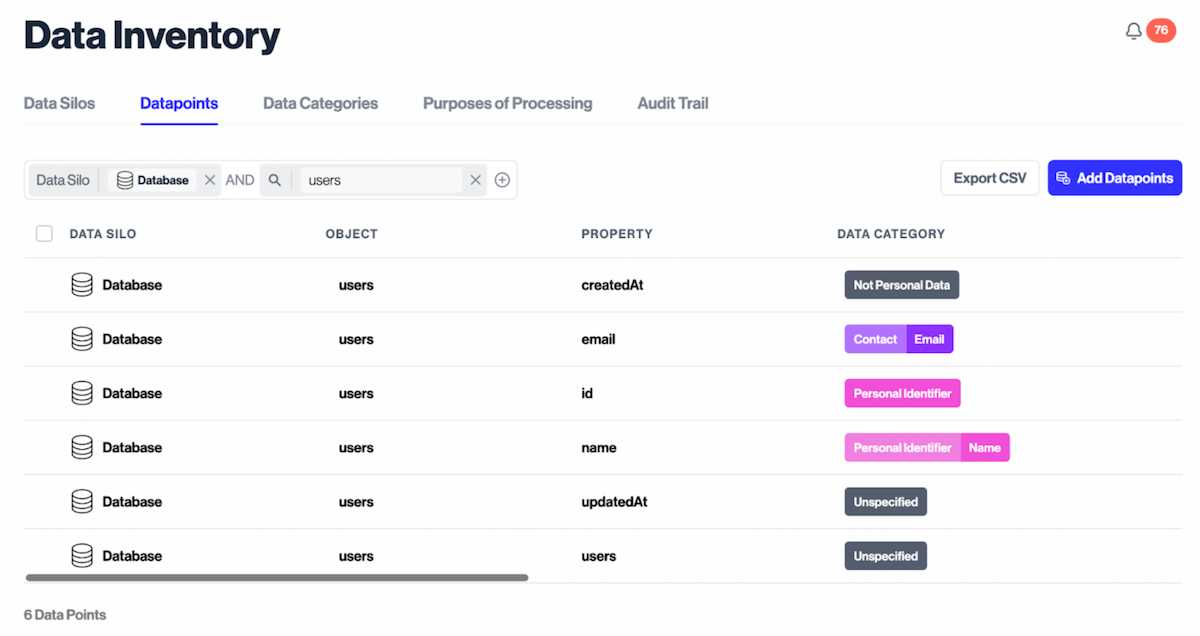
Adding a Datapoint Discovery Plugin is very similar to adding a Silo Plugin, just using a type of `DATA_POINT_DISCOVERY` instead:
resource "transcend_data_silo" "aws" { type = "amazonS3" plugin_configuration { enabled = true type = "DATA_POINT_DISCOVERY" schedule_frequency_minutes = 1440 # 1 day schedule_start_at = "2022-09-06T17:51:13.000Z" schedule_now = false } # ...other fields... } # ...other resources...
In this example, we set up AWS to scan for personal data in Amazon S3.
Datapoint Classification Plugins
Lastly, we support Datapoint Classification Plugins that can sample the data in your datastores. This is especially powerful when combined with the Datapoint Discovery Plugins that find the schemas of your internal systems.
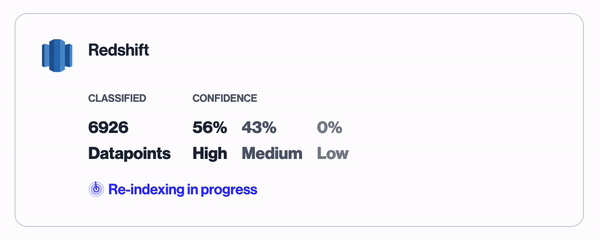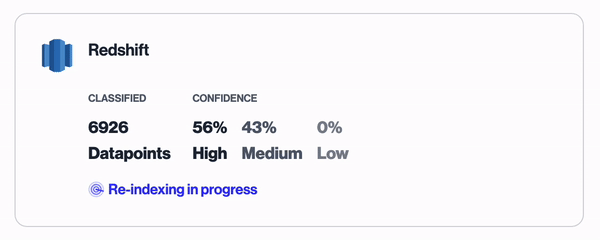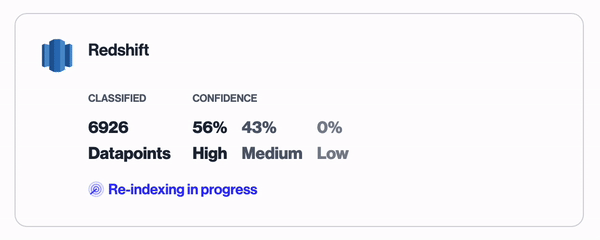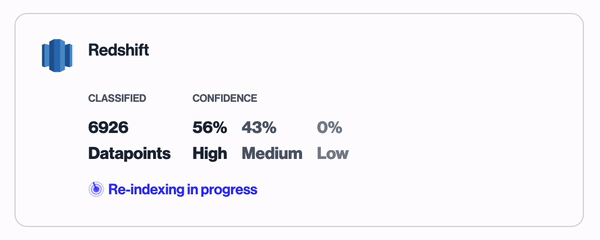
The results of the classification of datapoints in a Redshift database
In the above example, a Redshift database is being scanned. Each column under each table is sampled and our classifier attempts to classify the data category that each column belongs to. Each classification comes with a confidence rating to make triaging the findings easier.
Classification with complete security
One great part of this classification process is the security model. By using our end-to-end encryption gateway, Sombra, Transcend never needs to see the sample data in any of your systems. Likewise, Transcend never needs to have direct access to your databases nor any means of connecting to them even if we did have access.
All communication from Transcend to your database or other internal systems happens through Sombra, and all data that flows from Sombra back to Transcend will not contain any personal data that we would have access to. If personal data is ever returned, it is encrypted by the encryption gateway with keys from your Key Management System, which Transcend does not have access to.
Here’s a complete example, using Terraform, of setting up a PostgreSQL database using Amazon RDS in a private subnet of a VPC and connecting it to Transcend:
locals { subdomain = "https-test" # You should pick a hosted zone that is in your AWS Account parent_domain = "sombra.dev.trancsend.com" # Org URI found on https://app.transcend.io/infrastructure/sombra organization_uri = "wizard" } ###################################################################################### # Create a private network to put our database in with the sombra encryption gateway # ###################################################################################### module "vpc" { source = "terraform-aws-modules/vpc/aws" version = "~> 2.18.0" name = "sombra-example-https-test-vpc" cidr = "10.0.0.0/16" azs = ["us-east-1a", "us-east-1b"] private_subnets = ["10.0.101.0/24", "10.0.102.0/24"] public_subnets = ["10.0.201.0/24", "10.0.202.0/24"] database_subnets = ["10.0.103.0/24", "10.0.104.0/24"] enable_nat_gateway = true enable_dns_hostnames = true enable_dns_support = true create_database_subnet_group = true create_database_subnet_route_table = true } ####################################################################### # Deploy a Sombra encryption gateway and register it to a domain name # ####################################################################### data "aws_route53_zone" "this" { name = local.parent_domain } module "acm" { source = "terraform-aws-modules/acm/aws" version = "~> 2.0" zone_id = data.aws_route53_zone.this.id domain_name = "${local.subdomain}.${local.parent_domain}" } variable "tls_cert" {} variable "tls_key" {} variable "jwt_ecdsa_key" {} variable "internal_key_hash" {} module "sombra" { source = "transcend-io/sombra/aws" version = "1.4.1" # General Settings deploy_env = "example" project_id = "example-https" organization_uri = local.organization_uri # This should not be done in production, but allows testing the external endpoints during development transcend_backend_ips = ["0.0.0.0/0"] # VPC settings vpc_id = module.vpc.vpc_id public_subnet_ids = module.vpc.public_subnets private_subnet_ids = module.vpc.private_subnets private_subnets_cidr_blocks = module.vpc.private_subnets_cidr_blocks aws_region = "us-east-1" use_private_load_balancer = false # DNS Settings subdomain = local.subdomain root_domain = local.parent_domain zone_id = data.aws_route53_zone.this.id certificate_arn = module.acm.this_acm_certificate_arn # App settings data_subject_auth_methods = ["transcend", "session"] employee_auth_methods = ["transcend", "session"] # HTTPS Configuration desired_count = 1 tls_config = { passphrase = "unsecurePasswordAsAnExample" cert = var.tls_cert key = var.tls_key } transcend_backend_url = "https://api.dev.trancsend.com:443" # The root secrets that you should generate yourself and keep secret # See https://docs.transcend.io/docs/security/end-to-end-encryption/deploying-sombra#6.-cycle-your-keys for information on how to generate these values jwt_ecdsa_key = var.jwt_ecdsa_key internal_key_hash = var.internal_key_hash tags = {} } ###################################################################### # Create a security group that allows Sombra to talk to the database # ###################################################################### module "security_group" { source = "terraform-aws-modules/security-group/aws" version = "~> 4.0" name = "database-ingress" vpc_id = module.vpc.vpc_id # ingress ingress_with_cidr_blocks = [ { from_port = 5432 to_port = 5432 protocol = "tcp" description = "PostgreSQL access from private subnets within VPC (which includes sombra)" cidr_blocks = join(",", module.vpc.private_subnets_cidr_blocks) }, ] } ################################################### # Create a sample postgres database using AWS RDS # ################################################### module "postgresDb" { source = "terraform-aws-modules/rds/aws" version = "~> 5.0" allocated_storage = 5 engine = "postgres" engine_version = "11.14" family = "postgres11" major_engine_version = "11" instance_class = "db.t3.micro" multi_az = true db_subnet_group_name = module.vpc.database_subnet_group vpc_security_group_ids = [module.security_group.security_group_id] skip_final_snapshot = true deletion_protection = false apply_immediately = true identifier = "some-postgres-db" username = "someUsername" db_name = "somePostgresDb" } ####################################################### # As Sombra can talk to the database, we can create a # # data silo using the private connection information. # ####################################################### resource "transcend_data_silo" "database" { type = "database" plugin_configuration { enabled = true type = "DATA_POINT_DISCOVERY" schedule_frequency_minutes = 1440 # 1 day schedule_start_at = "2022-09-06T17:51:13.000Z" schedule_now = false } secret_context { name = "driver" value = "PostgreSQL Unicode" } secret_context { name = "connectionString" value = join(";", [ "Server=${module.postgresDb.db_instance_address}", "Database=${module.postgresDb.db_instance_name}", "UID=${module.postgresDb.db_instance_username}", "PWD=${module.postgresDb.db_instance_password}", "Port=${module.postgresDb.db_instance_port}" ]) } }
Notice that the database has a security group setup such that it can only be talked to from within the Virtual Private Cloud. Also, note that the Sombra encryption gateway is given permissions to talk to the database, but not any external Transcend system.
Proactively managing new sources of personal data
Finding user data in existing systems is cool. But do ya know what’s even cooler? Proactively labeling your data classifications and purposes as you add new features and syncing that data to Transcend. You can eliminate the need to triage our classifications by just telling us what the classifications are.
This can be done with both Terraform and the CLI, but this is where the CLI really shines. Our customers like Clubhouse have even created database client libraries where they can encode privacy information directly into their schema definitions. During their deploys, they extract this data into a YAML file that the CLI syncs to Transcend.
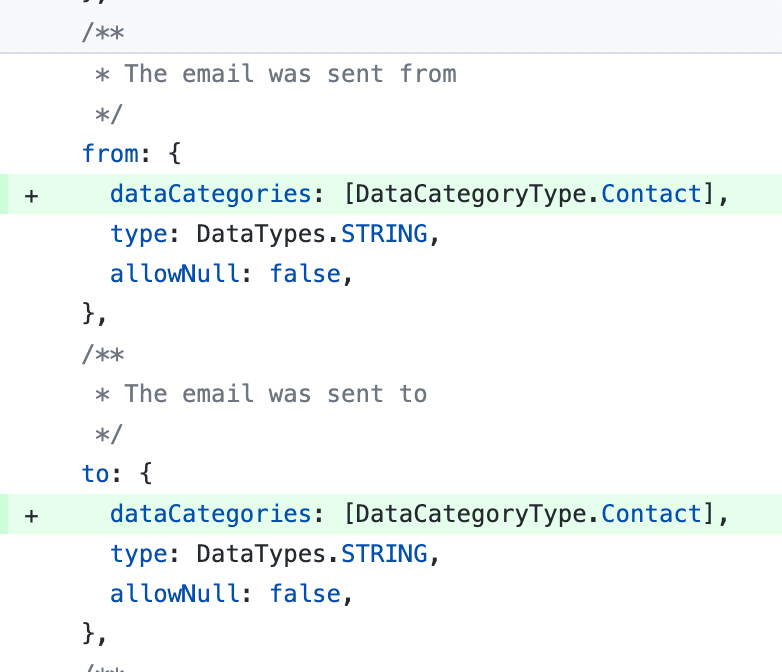
Here’s an example of a change in our codebase where we use an extension of Sequelize to define some fields on an email-related model. As the `from` and `to` fields of an email may contain personal email addresses, we labeled this data directly in our schema.
During a deploy, we extract the metadata about each database model and create a `transcend.yml` file containing a data point declared like:
- title: Communication key: dsr-models.communication description: A communication message sent between the organization and data subject fields: ...other fields ... - key: from title: from categories: - name: CONTACT category: CONTACT - key: to title: to categories: - name: CONTACT category: CONTACT
The CI job then syncs this data to Transcend, where there will be a data silo for the database with datapoints for the `from` and `to` columns listed as contact information.
Continuously scanning for personal data sources
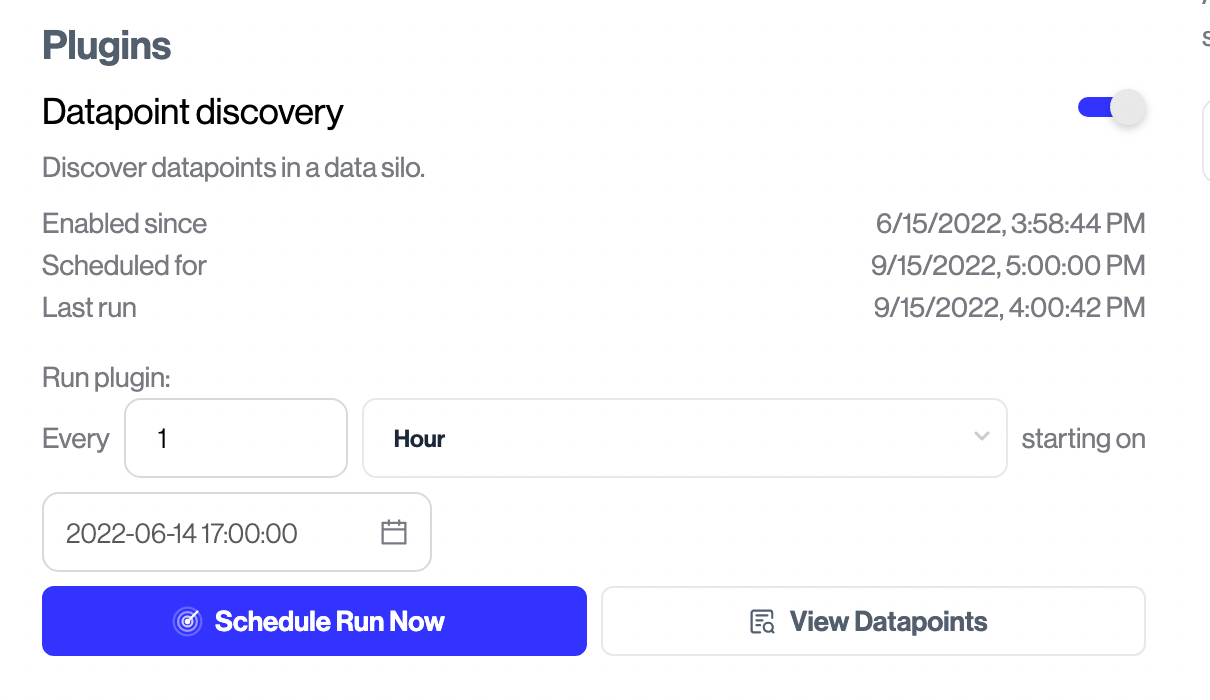
In the “Retroactively Finding and Classifying Personal Data” section above, we showed how Transcend makes it easy to find and classify personal data in your existing systems. But what about going into the future?
- What about when your Go To Market team adds a new tracking tool “just to test it out” and forgets to let your security owners know?
- Or what about if an engineering project slips through the cracks and doesn’t proactively note all personal data it stores?
- Or what if your ideal process is that engineering builds the tooling and that legal uses the scanning/classification tooling to label the data before the project fully launches (as opposed to engineering labeling the data as described in the previous section)?
Because our scanners and classifiers can run on a schedule, it’s easy to stay continuously compliant. Let the Okta plugin discover that new tracking tool. Let the AWS plugin notify you when a new database is created. Let a database plugin scan the databases for any new personal data that might appear.
Labeling data shouldn’t be a once per year affair, and it definitely shouldn’t be a “I’ll do it when we’re getting audited for privacy violations” affair. With Transcend, you can rest easy knowing that your data map will always be up to date.
About Transcend
Transcend is the company that makes it easy to encode privacy across your entire tech stack. Our mission is to make it simple for companies to give users control of their data.
Automate data subject request workflows with Privacy Requests, ensure nothing is tracked without user consent using Transcend Consent, or discover data silos and auto-generate reports with Data Mapping.


By David Mattia